Download Backout Plan Template & Protect Your Business

A routine update can turn into a business problem fast. At 4 PM on a Friday, a law office loses access to its document system. A dental practice can't reach patient files. A finance team suddenly can't trust the numbers on screen because a line-of-business application started throwing errors right after a patch.
That moment tells you whether your business has a plan or just optimism.
A backout plan template is the document that decides what happens next. Not in theory. In the hour when your staff is waiting, clients are calling, and someone on the IT side is trying to answer the most expensive question in the room: do we fix forward, or do we roll back now?
Most Central Florida businesses already know they need backups. Fewer have a rollback process that is clear enough to use under pressure, approved by leadership, and tied to security response. That gap matters most in regulated environments like law, finance, healthcare, and multi-site operations where one bad change can ripple across users, vendors, and compliance obligations.
When Good IT Changes Go Bad
A failed change rarely starts with drama. It starts with a normal ticket.
A vendor approves a patch. Someone schedules an after-hours deployment. The change looks small enough to be safe. Then the phones start.

In Orlando and Winter Springs, I’ve seen the same pattern across professional firms and medical practices. The first few minutes get wasted debating whether the issue is temporary. Then people start trying side fixes. Someone restarts a service. Someone else blames the internet. Meanwhile, damage comes from delay.
What business owners feel
You don't experience a failed deployment as a technical event. You experience it as:
- Interrupted revenue when staff can't work
- Client-facing confusion when systems go offline
- Compliance exposure when access, logging, or protected data handling becomes uncertain
- Weekend burnout when a simple rollback turns into an improvised recovery effort
A proper backout plan turns that mess into a sequence.
A backout plan isn't an IT formality. It's a decision tool for protecting operating hours, client trust, and recoverability.
That distinction matters. If your team treats rollback as “restore from backup if needed,” the business is still exposed. Restore from what backup? Approved by whom? In what order? What if the failed change touched a vendor-managed tool, Microsoft 365 policy, endpoint stack, or cloud platform dependency?
Why generic templates fail under pressure
Most downloadable templates are too shallow. They list placeholders for “backout steps” but don't force the hard decisions in advance.
What works better is a template built around the business context:
- Your critical applications
- Your vendor dependencies
- Your escalation chain
- Your compliance requirements
- Your acceptable downtime
If you're already reviewing changes to cloud systems or regulated data workflows, it's worth reading this practical guide on how to avoid failure. The lesson applies beyond migrations. Problems usually begin before the change window, not during it.
The difference between a scare and an outage
Two firms can suffer the same failed update and get very different outcomes.
One spends the evening guessing. The other opens a written plan, checks the trigger criteria, gets authorization, rolls back in sequence, validates the restore, and watches the environment for instability.
That's why a backout plan template belongs in business continuity, not just change management. It gives your team a repeatable response before the next patch, server migration, network change, or cloud rollout goes sideways.
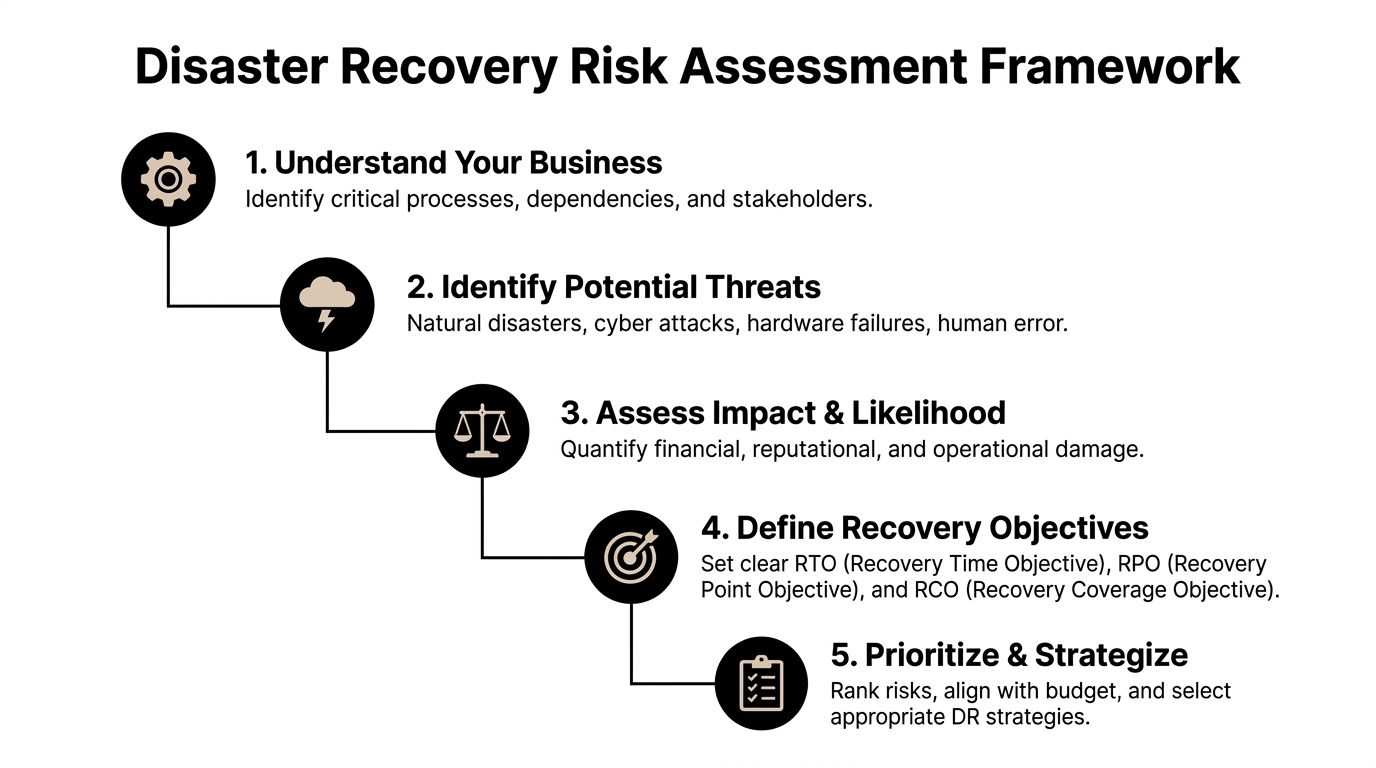
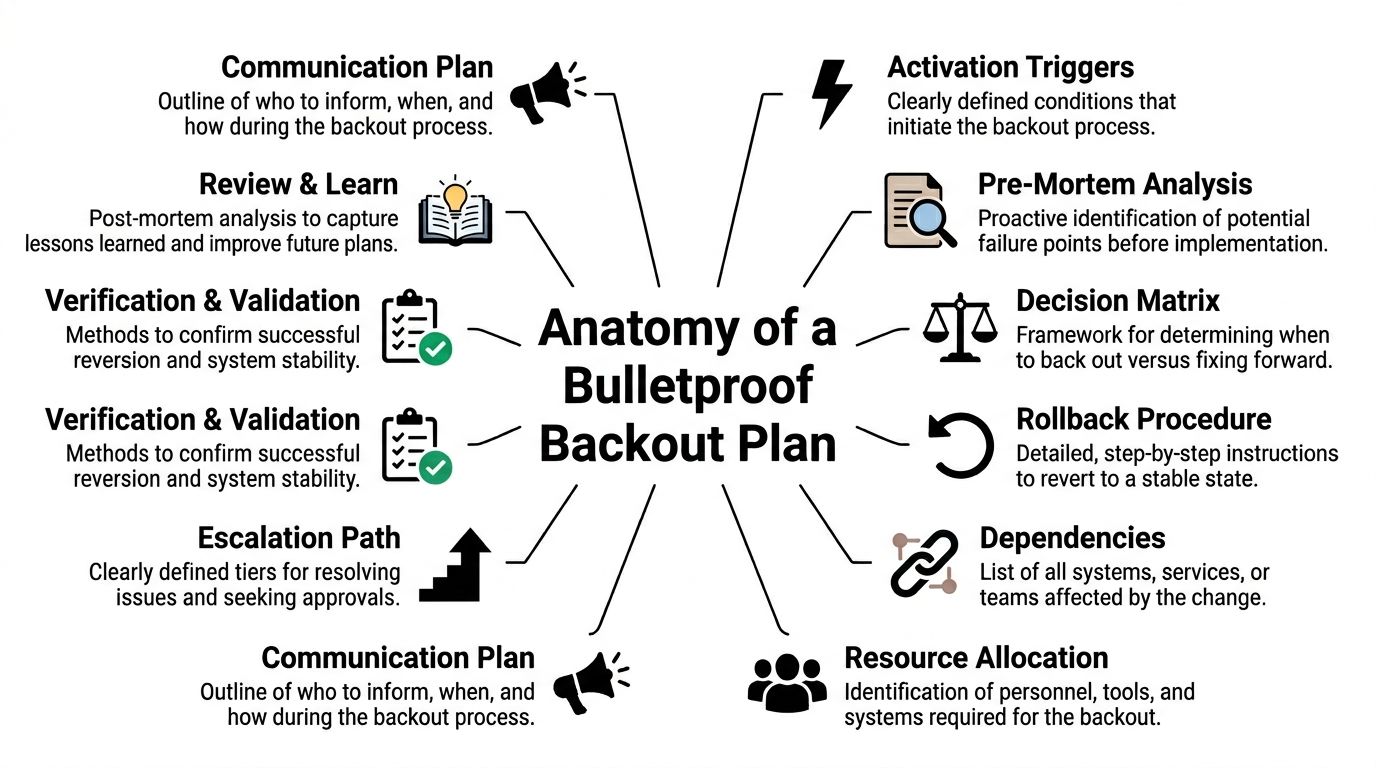
Anatomy of a Bulletproof Backout Plan Template
A strong backout plan template isn't long because it looks impressive. It's detailed because ambiguity causes downtime.
The template should answer one question cleanly: if this change fails, who decides, who acts, what gets restored, and how do we prove the business is stable again?
Start with scope
Scope means the exact systems, users, data sets, integrations, and locations covered by the plan.
This sounds basic, but weak plans fail here first. If your accounting application depends on identity services, a database server, and a vendor-hosted connector, the scope has to name all three. If your Winter Springs office can tolerate longer downtime than your Orlando front desk, the plan should say so.
A simple scope table helps:
| Item | What to document |
|---|---|
| Primary system | Application, server, cloud service, or network component being changed |
| Dependent systems | Authentication, storage, integrations, print, VoIP, vendor tools |
| Business units affected | Legal, billing, patient scheduling, field operations, finance |
| Locations affected | Office-by-office impact if you operate across sites |
| Out of scope | Systems explicitly not covered by this rollback plan |
Build the plan on recoverability, not hope
For regulated businesses, backup discipline is part of the foundation. Under the HIPAA backup planning requirements and 3-2-1 backup rule, backout planning should sit on 3 copies of data, 2 media types, and 1 offsite copy. That same reference notes that HIPAA requires data backup plans with defined RPOs and RTOs.
For a practice, firm, or financial office, that means your template should state:
- Recovery Time Objective as the maximum acceptable outage
- Recovery Point Objective as the acceptable amount of data loss
- Backup source that supports rollback
- Retention logic that aligns with your operating and compliance needs
If you want a useful companion to this thinking, a broader technology risk management framework can help leadership connect operational change risk to governance, vendors, and resilience.
Define triggers before the outage
Triggers are the predefined conditions that start the backout process.
Good triggers are measurable. Bad triggers are emotional.
Examples of usable trigger language include:
- RTO breach risk if the service won't be restored within the allowed downtime
- Critical function failure such as login, charting, billing, or matter access
- Performance degradation that materially affects operations
- Security concern if the change causes suspicious behavior, unauthorized configuration drift, or logging failure
The trigger should remove debate. If the condition is met, the team acts.
Name the decision makers and the doers
A professional template separates authority from execution.
Use named roles, not job titles alone, if possible. If a key person is unavailable, list a backup approver. Most businesses need these roles covered:
- Change owner who understands the intended deployment
- Business approver who can judge operational impact
- Rollback authority who can authorize the backout
- Technical executor who runs the rollback steps
- Security contact who determines whether the event is operational, malicious, or both
- Communications owner who updates internal stakeholders and external parties if needed
A useful template also records vendor contacts, support contracts, and escalation numbers in the same document. Don't make your team hunt for them while systems are down.
Include communications, dependencies, and validation
Many failures get technically fixed before they get operationally closed. Users still don't know what happened, vendors are still out of sync, and nobody has confirmed the restored system is trustworthy.
Your template should include:
Communication plan
List who gets notified, by what method, and at what stage. Separate internal staff, leadership, vendors, and client-facing communications.
Dependency map
Document external providers, identity systems, firewalls, endpoint tooling, cloud workloads, and line-of-business connectors.
Verification checklist
Use a short test list that proves business usability after rollback:
- Authentication works
- Core transactions complete
- Recent data is present
- Audit logs are intact
- Security controls are functioning
For teams that need a working foundation, this disaster recovery plan template is a practical starting point. The key is to adapt it to rollback-specific decisions, not just backup recovery.
Creating Your Step-by-Step Rollback Procedure
The rollback procedure is the part people think they have until they need it. Then they discover they've documented the intention to roll back, not the actual path.
A reliable backout plan template needs a procedure that an experienced engineer can execute quickly and another engineer can follow under stress without improvising.

Before the change window opens
The best rollback starts before the deployment.
The VA rollback guidance describes a rigorous process that includes defining triggers such as an RTO breach greater than 4 hours, getting CIO authorization, restoring from a pre-patch snapshot, and verifying integrity. That same guidance notes 92% success rates when pre-backups are verified, compared with 65% for ad-hoc restores.
That gap is the difference between procedure and guesswork.
The pre-change checklist that matters
Use a written checklist before any material change:
Capture a baseline
Record the current system state. That includes version numbers, configuration snapshots, service status, active integrations, and known-good test results.Verify the backup, not just its existence
Confirm the restore point is recent, complete, and accessible. A backup you haven't verified is only a file with good intentions.Inventory dependencies
List what will break if the rollback happens. Include cloud apps, identity providers, endpoint agents, shared drives, print services, vendor connectors, and remote sites.Stage the rollback commands
If your team uses tools like Ansible, PowerShell, hypervisor snapshots, or vendor rollback packages, prepare them in advance. The change window isn't the time to write commands from memory.Assign real people to each action
One person approves. One executes. One validates business functions. One owns communications.
Practical rule: If a rollback step requires memory, it isn't documented well enough.
Decide when to fix forward and when to back out
Not every issue requires reversal. Some can be corrected in place. The problem is that teams often spend too long trying.
A compact decision matrix helps:
| Condition | Better choice |
|---|---|
| Core application unavailable | Back out |
| Minor defect with stable service | Fix forward if risk is low |
| Security control disabled by change | Back out and escalate to security |
| Unknown root cause during deployment | Back out |
| Vendor dependency failing with no confirmed workaround | Back out |
Business owners don't need every technical detail here. They do need confidence that the threshold for rollback is already agreed.
Execute the rollback in a controlled order
Rollback should follow a sequence, not a scramble.
Freeze additional changes
Stop all non-essential work on the affected system. Don't let a second technician introduce a second variable.
Get the formal go-ahead
If your plan requires executive, CIO, or delegated approval, get it and log the time. During incidents, missing approvals create audit and accountability problems later.
Restore the known-good state
That might mean reverting a snapshot, uninstalling a patch, reapplying a prior configuration, or restoring a previous cloud deployment package. Use scripted steps where possible.
Reconnect dependencies carefully
Bring back authentication, database links, integrations, and line-of-business services in the right order. A successful server rollback still fails the business if SSO, printing, or data exchange stays broken.
Validate more than uptime
A server that responds to ping isn't the same as a business service that's safe to use.
Use layered validation after the rollback:
- Technical checks such as service status, error logs, scheduled tasks, agent health
- Data integrity checks such as checksums, record consistency, or application-level validation
- Business checks such as opening a matter, posting a payment, viewing a chart, or processing a claim
- Security checks such as logging, MFA, endpoint telemetry, and alert flow
The federal guidance referenced above requires integrity verification and automated testing, not just restoration. That's a useful standard for any SMB. If your law firm can log in but document permissions are wrong, the rollback isn't complete. If your dental practice can access schedules but audit logs stopped writing, the rollback isn't complete.
Watch the system after the rollback
Immediate success can be misleading. A system may appear stable and fail again after users reconnect, synchronization resumes, or overnight jobs run.
Build a post-backout observation period into your template. During that window, the team should:
- Monitor application behavior
- Review security events
- Check integrations and vendor syncs
- Confirm user-reported issues are declining
- Document every action taken
Use plain language in the plan. “Observe for stability” is too vague. “Monitor authentication, transaction processing, and security logging during the observation window” is better.
A good rollback procedure isn't elegant. It's usable. That's what counts when the phones are ringing.
Backout Plans in Action Real-World Scenarios
A backout plan template becomes valuable when it matches the kind of failures your business is likely to face. That's where many firms miss. They use one generic template for every change, every office, and every vendor.
That approach breaks down fast in multi-site and regulated environments.
Scenario one: a law firm loses access after a security update
A Plano law firm pushes a Microsoft 365-related security change late in the day. Within minutes, staff can't reliably access email and shared documents. Attorneys are still working active matters, and support staff can't tell whether the issue is identity-related, endpoint-related, or vendor-side.
A weak plan would say “contact Microsoft and troubleshoot.”
A useful plan would do something tighter:
- Freeze additional policy changes
- Check whether the issue meets the rollback trigger based on business impact
- Review the dependency list for identity, document access, and endpoint controls
- Use the vendor-inclusive checklist to involve the external provider immediately
- Revert the specific change package or policy set
- Validate matter access, email flow, and security logging before returning users to normal operations
The vendor angle matters more than most firms realize. According to the VA-based rollback reference for multi-location operations/viab_1_9_installation_back-out_rollback_plan.pdf), 35% of incidents stem from unmanaged third-party vendor updates, and generic templates often fail multi-site businesses because they lack location-specific RTO variances. That same reference notes this can lead to 15-20% higher downtime costs.
For a law office, that means one office may need faster restoration than another because court deadlines, intake, and billing aren't equally sensitive.
Scenario two: a dental practice struggles after a cloud migration
An Orlando dental practice moves a clinical application or imaging workload to a new cloud environment. The migration technically completes, but users report slow retrieval, intermittent file errors, and uncertainty about whether recent patient data is fully consistent.
This isn't the moment for vague confidence.
A practical backout plan would ask:
If patient care operations are impaired and data validation isn't clean, why stay in the broken target environment?
For a practice, rollback decisions should include both operations and compliance logic. If the restored environment can be proven stable and the migrated environment can't be trusted yet, revert fast and investigate later.
The plan should identify:
- the last verified restore point
- the sequence for reconnecting workstations and imaging systems
- who confirms application usability on the clinical side
- how to document the event for compliance review
Scenario three: a multi-location industrial company loses network stability
A Central Florida industrial business changes network switch configurations across more than one site. The result isn't a full outage. It's worse in some ways. Intermittent connectivity, broken device communication, and site-by-site inconsistency.
Generic backout plans usually collapse here. They assume one system, one site, one rollback. Real operations aren't that neat.
A stronger template handles the situation by breaking rollback into location-aware stages:
| Site condition | Backout response |
|---|---|
| Primary site unstable | Roll back immediately to last known-good config |
| Secondary site degraded but usable | Hold, assess impact, then roll back if threshold is met |
| Vendor-managed segment involved | Escalate using vendor contact and rollback ownership list |
| Shared dependency affected across sites | Coordinate rollback centrally, validate locally |
For industrial and field-service organizations, that site-by-site detail keeps one bad network change from becoming a company-wide event.
What all three examples have in common
The best backout plan template isn't generic and isn't purely technical.
It accounts for:
- Business function first
- Vendor participation
- Location-specific recovery expectations
- Clear authority to reverse course
- Validation that proves the business is usable again
That's what makes the document operational instead of decorative.
Integrating Your Backout Plan with Cyber Incident Response
A backout plan that only covers failed IT changes is incomplete.
Sometimes the “bad update” isn't bad code. It's malicious activity, unauthorized access, a compromised admin account, or a ransomware event that used normal change paths to create abnormal damage. In those cases, rolling back without security oversight can make the problem worse.

Why the old model is too narrow
The old model says: change failed, restore previous state, move on.
That works only if the event is purely operational. It fails if:
- the rollback source is already compromised
- the failed change reopened a known vulnerability
- attacker persistence survives the backout
- logs and telemetry are incomplete
- the “deployment issue” was unauthorized change activity
The IT Toolkit 2025 disaster recovery guidance identifies a major gap here. It notes that only 36% of SMBs have backout plans designed for cyber incidents, even though SMBs faced 43% of cyberattacks, and templates rarely define decision authority during an active threat or integrate with SOC-monitored reversions.
That's the blind spot.
Add cyber decision points to the template
Your backout plan template should include a branch for security review before rollback proceeds.
That branch should answer questions like:
- Was this change approved through normal process?
- Do logs show expected admin behavior?
- Could the failure indicate tampering rather than ordinary error?
- Will rollback restore a vulnerable state that still needs containment?
- Who has authority to approve backout during an active threat?
If those questions are missing, the team may restore service quickly while preserving the attacker’s foothold.
During a suspected cyber event, speed matters, but sequence matters more. Contain, assess, then revert with evidence.
What SOC-linked rollback looks like in practice
In a mature process, rollback is coordinated with security operations.
That doesn't mean every failed patch becomes a crisis. It means the plan creates an explicit handoff when indicators point to malicious activity or uncertainty.
A workable integration usually includes:
Security escalation path
List who gets engaged if the event may be cyber-related. That can be an internal security lead, an external incident responder, or a 24/7 SOC.
Evidence preservation
Before rollback wipes away traces, capture logs, snapshots, alerts, and administrative activity records needed for investigation.
Safe-state validation
After rollback, confirm the environment isn't just operational. Confirm endpoint telemetry, MFA, logging, alerting, and access controls are functioning as expected.
Compliance follow-up
For firms handling regulated data, document what changed, who approved the action, what data was affected, and how system integrity was confirmed.
Businesses that need to formalize that connection should also review a practical incident response plan for max efficiency. A rollback plan and an incident response plan shouldn't live in separate universes.
A rollback can create security risk too
Some leaders assume rollback is always the safer option. It isn't.
Rolling back may re-enable a flawed configuration, restore a vulnerable application version, or undo a security control that was functioning correctly. That's why the template needs a short risk review before execution.
Use a simple compare-and-decide method:
| Question | If yes |
|---|---|
| Does rollback restore a previously exposed weakness? | Add compensating controls first |
| Is the current state potentially malicious? | Preserve evidence and involve security |
| Will rollback remove forensic data? | Capture what you need before action |
| Can the system be isolated before reversion? | Isolate to reduce spread risk |
The practical goal is resilience, not just restoration. A business owner in Orlando doesn't need a more technical rollback. They need one that won't trade downtime for security debt.
Keeping Your Plan Alive Testing and Maintenance
A backout plan template that isn't tested will fail at the worst time.
People change roles. Vendors change support paths. systems get renamed. Cloud workloads move. A rollback sequence that worked six months ago may now miss a dependency, an integration, or an approval step that your business relies on every day.
Test the plan the way your business operates
The Axcient disaster recovery planning guide for MSPs reports that organizations with tested plans achieve 75% faster recovery than those using ad-hoc responses. It also notes that setting clear RTOs, such as under 4 hours for most SMBs, and testing against them can cut recovery costs by up to 30%.
Those gains don't come from owning a template. They come from rehearsal.
What to test on a regular basis
Don't limit testing to “can we restore a server.”
Run practical drills that reflect business reality:
- Change rollback drill for a failed patch or software deployment
- Vendor failure drill where a third-party update has to be reversed
- Location-specific drill for one office or branch losing a critical service
- Security-linked drill where rollback and incident review happen together
A short test cadence table keeps this manageable:
| Test type | What success looks like |
|---|---|
| Technical rollback | System reverts cleanly and services restart correctly |
| Business validation | Staff can complete key workflows after rollback |
| Vendor escalation | Contacts respond and responsibilities are clear |
| Security validation | Logging, alerting, and access controls remain intact |
Track the right results
You don't need a pile of test paperwork. You need evidence that the plan works and keeps improving.
Focus on a few useful outputs:
RTO performance
Did the test complete within the target downtime window?
Recovery quality
Were users able to work, or did the rollback only restore partial function?
Documentation accuracy
Did the contact list, dependency map, and procedure match reality?
Improvement actions
What needs to be updated before the next test?
The best maintenance habit is simple. Every real incident and every test should change the document.
Tie testing to accountability
Many SMBs miss an easy win here.
Backout plan maintenance belongs in leadership review, not only in the IT queue. Quarterly business reviews are a good place to examine failed changes, test outcomes, vendor issues, and whether recovery objectives still match the business.
If you're building a formal practice around this, review how to test a disaster recovery plan. The same discipline applies to rollback readiness.
A living plan should be updated when:
- A critical system changes
- A new vendor is introduced
- An office is added or consolidated
- A compliance requirement shifts
- A test exposes confusion or delay
That cycle is what turns a backout plan template into an operating safeguard instead of a forgotten file.
If your business in Orlando, Winter Springs, or the surrounding Central Florida market needs a rollback plan that covers operations, vendors, compliance, and cyber response, Cyber Command, LLC can help you build and maintain one that works under pressure. The goal isn't just to recover. It's to keep your team productive, reduce avoidable downtime, and make every change safer before it goes live.