IT Security Services in Orlando FL: A 2026 Business Guide

You're probably not reading this because security is a hobby. You're reading it because something already happened, or almost did. A suspicious Microsoft 365 login. A fake invoice that looked real enough to fool accounting. A cyber insurance renewal that suddenly asks for proof of MFA, patching, and incident logging. Or a competitor in Orlando gets hit, and you realize your business would have a hard time answering one simple question: if an attack starts at 4:30 p.m. on a Friday, who takes over?
That's where most small and mid-sized companies in Central Florida get stuck. They've bought some tools, they have an IT person or provider, and they assume that means they're covered. In practice, that often means they have partial coverage, weak documentation, and no clear incident-response path. If you need a useful baseline before talking to a provider, this 2024 digital security guide is a solid plain-English refresher on the habits and controls that reduce avoidable risk.
Table of Contents
- Why Orlando Businesses Must Prioritize Cybersecurity
- Understanding Your Defensive Layers What Are IT Security Services
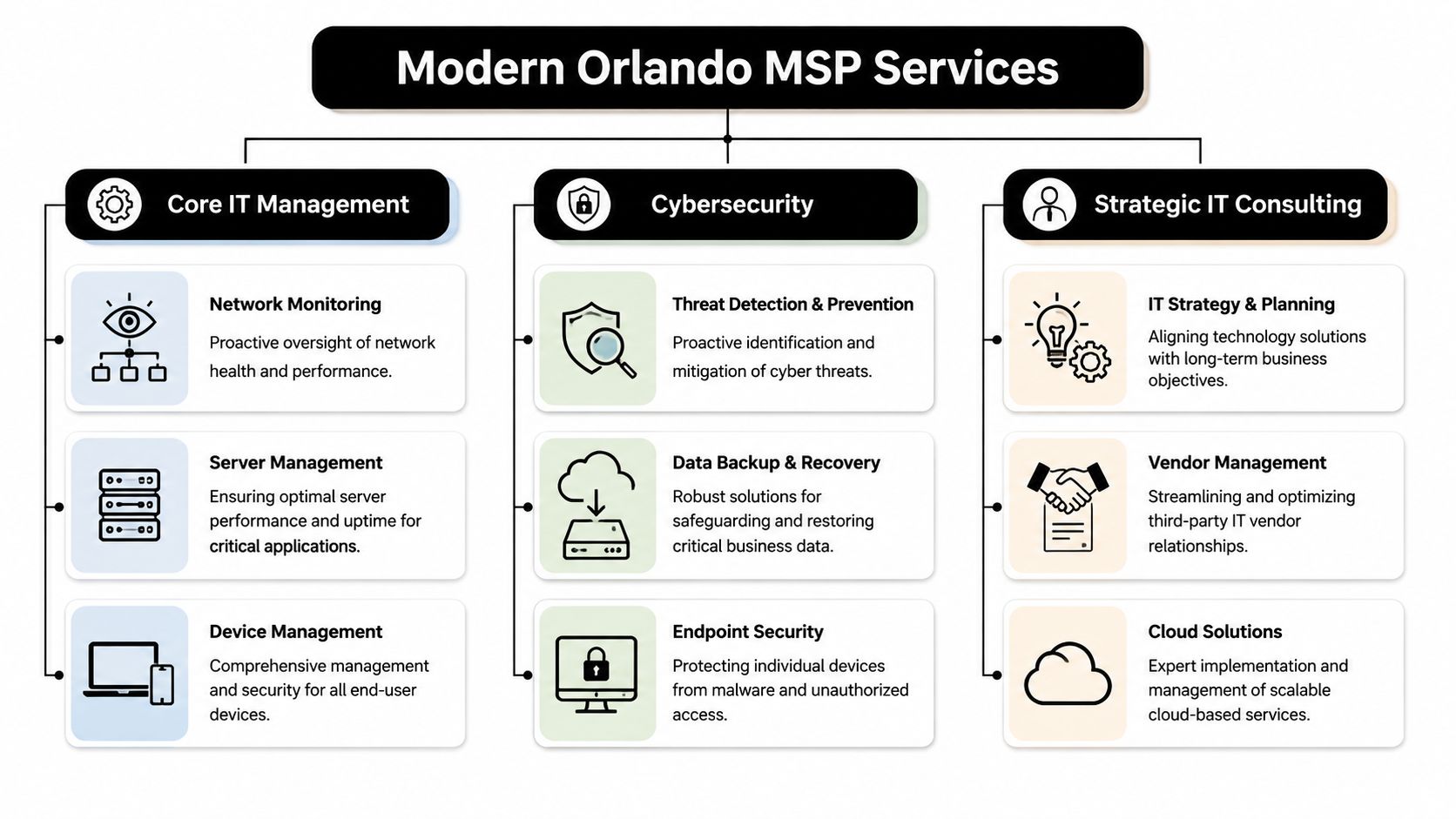
- The Core Security Services Every Orlando Business Needs
- Decoding IT Security Pricing Predictability vs Hidden Fees
- Choosing Your Orlando Security Partner Key Questions to Ask
- Industry-Specific Security Needs in Central Florida
- Frequently Asked Questions About IT Security
Why Orlando Businesses Must Prioritize Cybersecurity
A typical Orlando security scare doesn't start with a movie-style breach alert. It starts with a person. Someone in accounting gets an email that looks like it came from a vendor. A manager gets a password-reset prompt that appears normal. A front-desk employee clicks a link because the message mentions a missed shipment or a payroll issue.
That matters locally because Orlando's business mix creates a very specific risk profile. A local threat assessment says the area is shaped by high-value tourism infrastructure, dense hospitality and entertainment activity, a growing technology sector, and significant federal-contractor presence tied to nearby defense installations, and it identifies social engineering and phishing as the highest-volume initial access vector across sectors in Orlando's market (Orlando cybersecurity threat landscape analysis).
Why local context changes the security plan
A law office in Winter Springs doesn't face the same exposure as a restaurant group near the attractions corridor. A medical practice with several locations doesn't have the same attack surface as an engineering firm handling client drawings and bid documents. But they all share one problem: staff still interact with email, cloud apps, mobile devices, payment workflows, and outside vendors every day.
That's why generic “we have antivirus” thinking fails. The core issue isn't just malware. It's whether your business can:
- Spot suspicious behavior early: Before a phish turns into account takeover.
- Contain access quickly: Before one compromised user reaches file shares, email, and finance systems.
- Document what happened: So you can answer insurance, legal, and compliance questions later.
- Keep operating: Even while investigation and recovery are underway.
Orlando businesses don't need abstract cybersecurity theory. They need a response model that works when a real employee clicks the wrong thing during a normal workday.
What owners usually underestimate
Business owners often focus on prevention and overlook operations. They ask whether a provider installs protections. They don't ask what happens after detection, who is watching alerts after hours, or how evidence gets preserved if a claim, audit, or dispute follows.
That's the practical reason to prioritize cybersecurity in Orlando. The threat is local, the attack path is usually human, and the business impact shows up in downtime, missed revenue, disrupted scheduling, and stressful compliance cleanup.
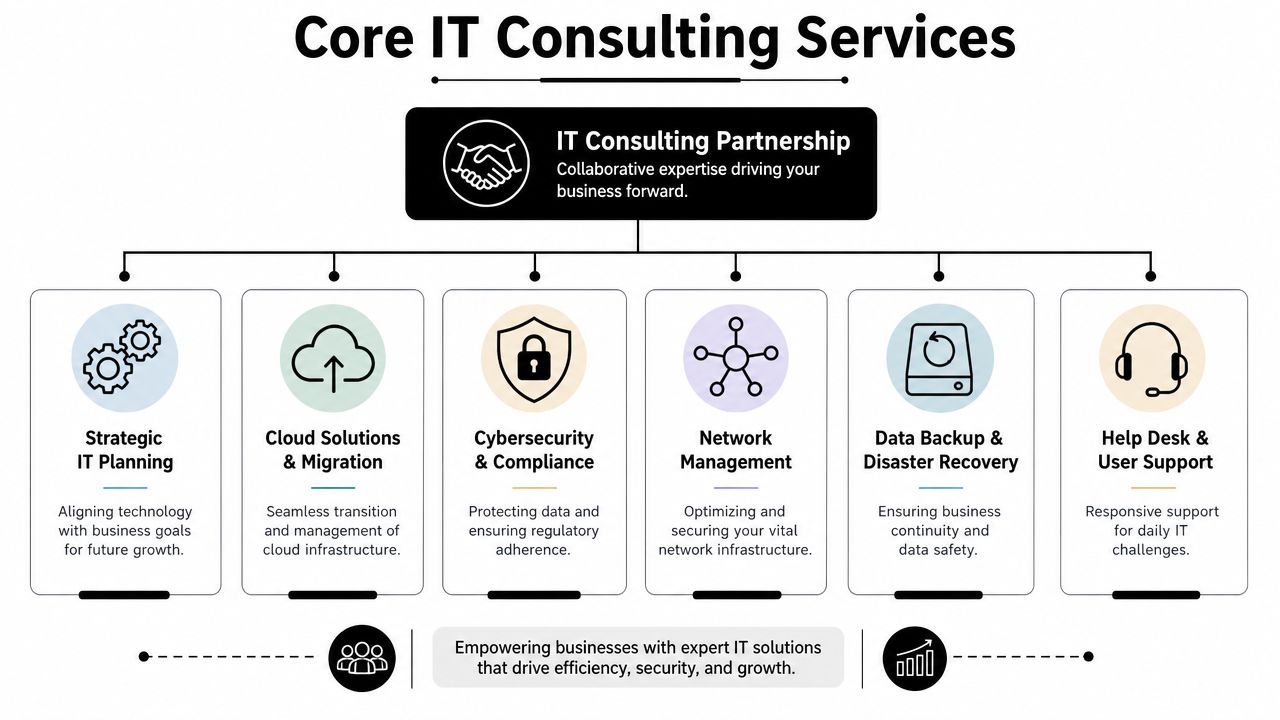
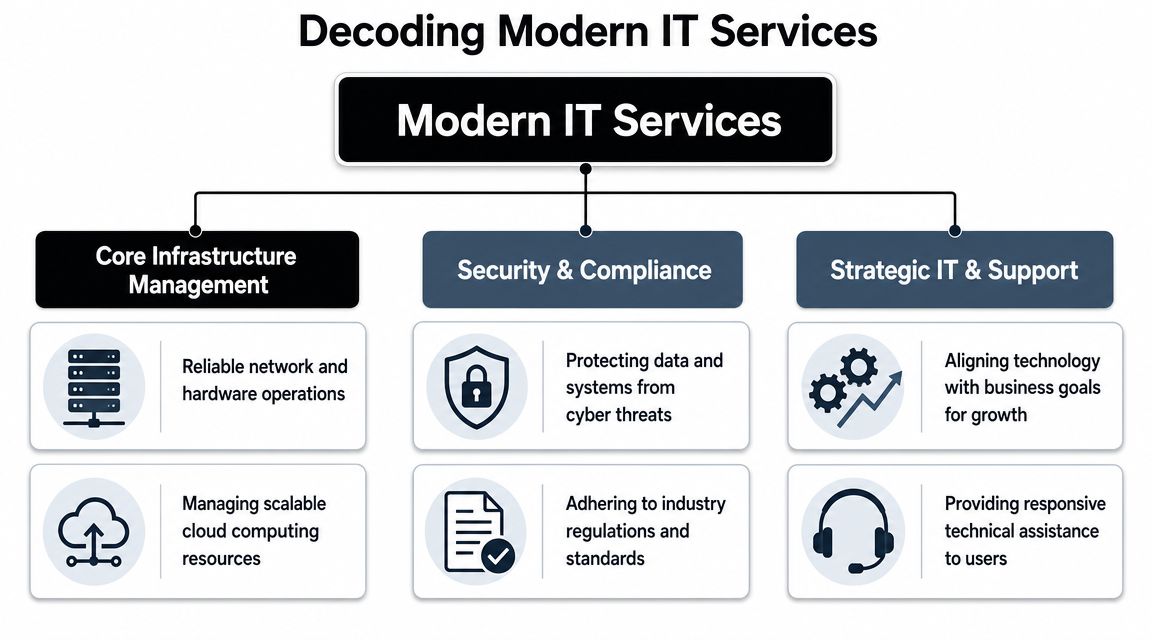
Understanding Your Defensive Layers What Are IT Security Services
Most business owners hear “IT security services” and think of one product. That's the wrong model. Security works more like building protection. You don't secure a facility with only a front-door lock. You use locks, cameras, alarms, badge access, guard procedures, and incident logs that all work together.
For Orlando-area businesses, the meaningful stack goes beyond antivirus or general IT support. Local market guidance points to a layered stack that includes intrusion detection, firewall hardening, managed access control, video surveillance, and continuous monitoring, reflecting the reality that many organizations here have both cyber and physical exposure.

Your business as a castle
Think of your environment in layers:
- Outer wall: Your firewall and network controls. These filter and restrict traffic before it reaches internal systems.
- Moat and drawbridge: Access control. This includes MFA, role-based access, account policies, and joiner-mover-leaver discipline.
- Inner keep: Endpoint security on laptops, desktops, and mobile devices where staff work.
- Treasury: Data protection. Backups, retention, encryption policies, and permission boundaries around sensitive files.
- Watchtower: Monitoring and response. Someone has to review alerts, investigate anomalies, and act fast.
A lot of businesses buy pieces of this but never integrate them. That creates blind spots. The firewall may log a strange connection, the endpoint may show unusual activity, and the access system may record a suspicious login, but if nobody correlates those events, the incident gets investigated too late.
What a real layered stack looks like
A workable security program usually includes a mix of controls and ongoing services:
- Preventive controls such as hardened firewalls, MFA, email filtering, and endpoint protections.
- Detective controls such as centralized logging, intrusion detection, and user activity review.
- Response controls such as isolation procedures, account lockouts, escalation paths, and recovery steps.
- Evidence controls such as incident logs, patch records, and access documentation.
If you're reviewing your environment, a formal vulnerability assessment process is often the fastest way to identify which layer is weak first.
Practical rule: If a provider can only name products, but can't explain how alerts move from detection to containment to documentation, you're not looking at a mature security service.
There's also a newer human-side challenge. Staff are no longer just spotting fake emails. They're seeing manipulated images, voice clips, and synthetic media used in fraud attempts. Training employees to question unusual requests matters more than ever, and resources on spotting AI-created media can help teams sharpen that judgment.
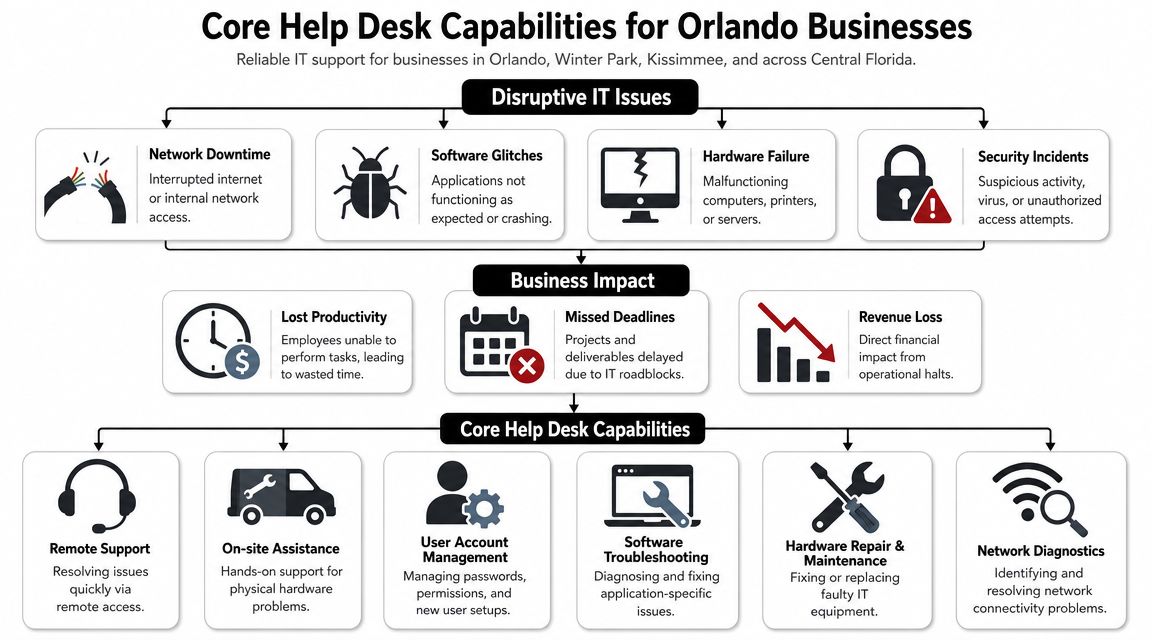
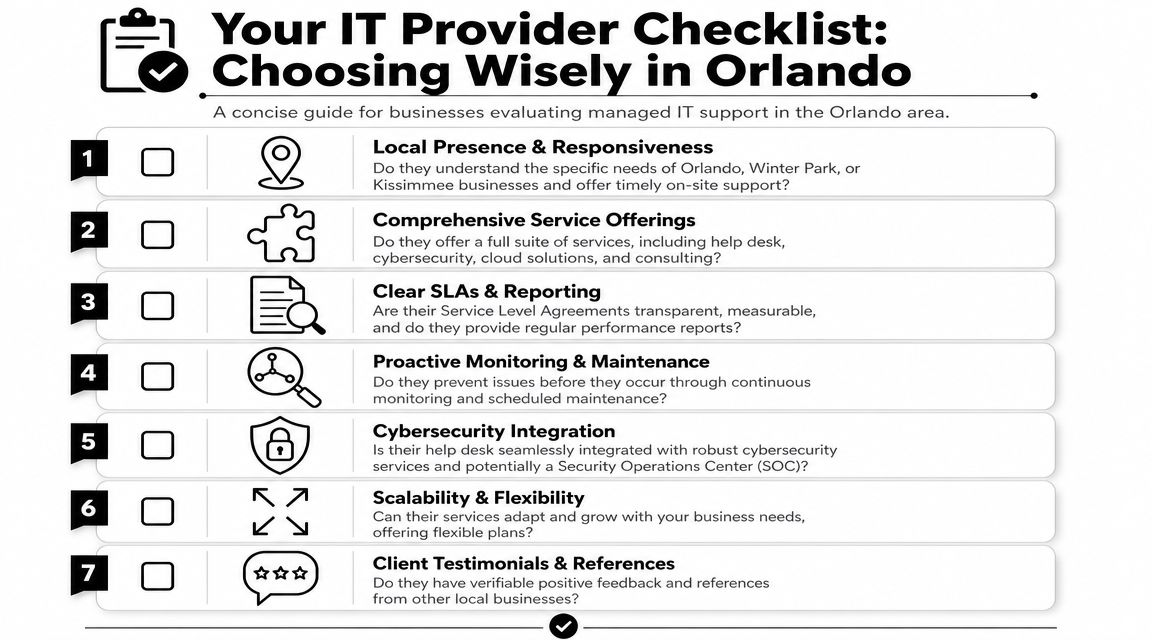
The Core Security Services Every Orlando Business Needs
A Monday morning ransomware event rarely starts with dramatic warnings. It starts with a locked laptop, a failed login, a phone call from accounting, and a manager trying to decide whether the issue is isolated or spreading. The businesses that recover fastest usually have three things in place before that moment: active monitoring, a response plan people can execute under pressure, and documentation that stands up to insurer and auditor questions.

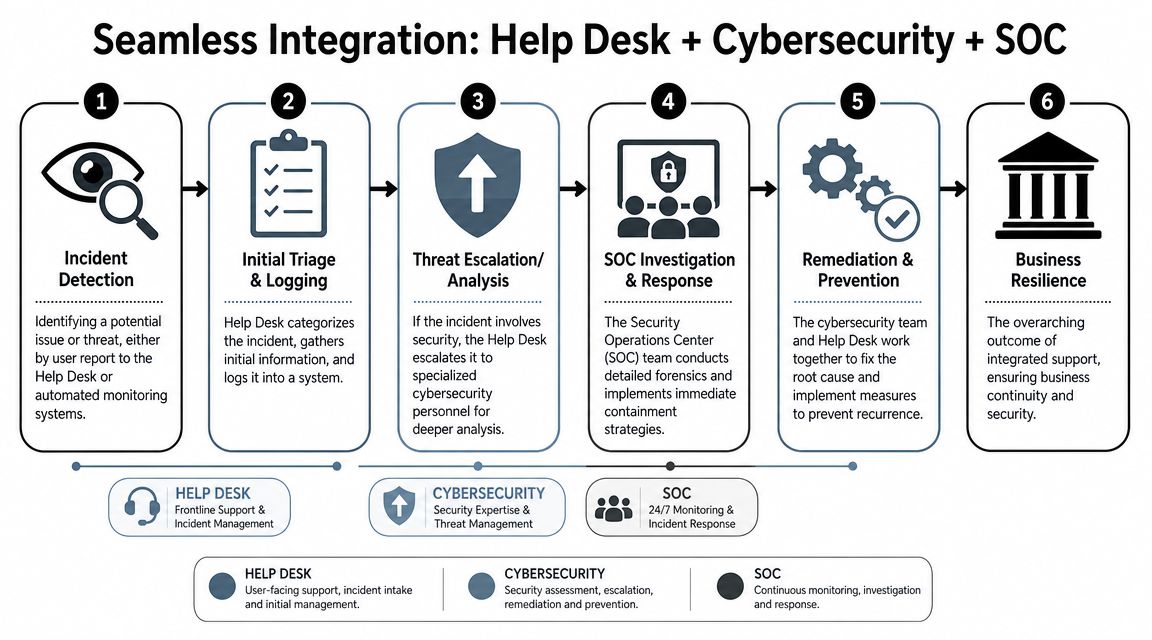
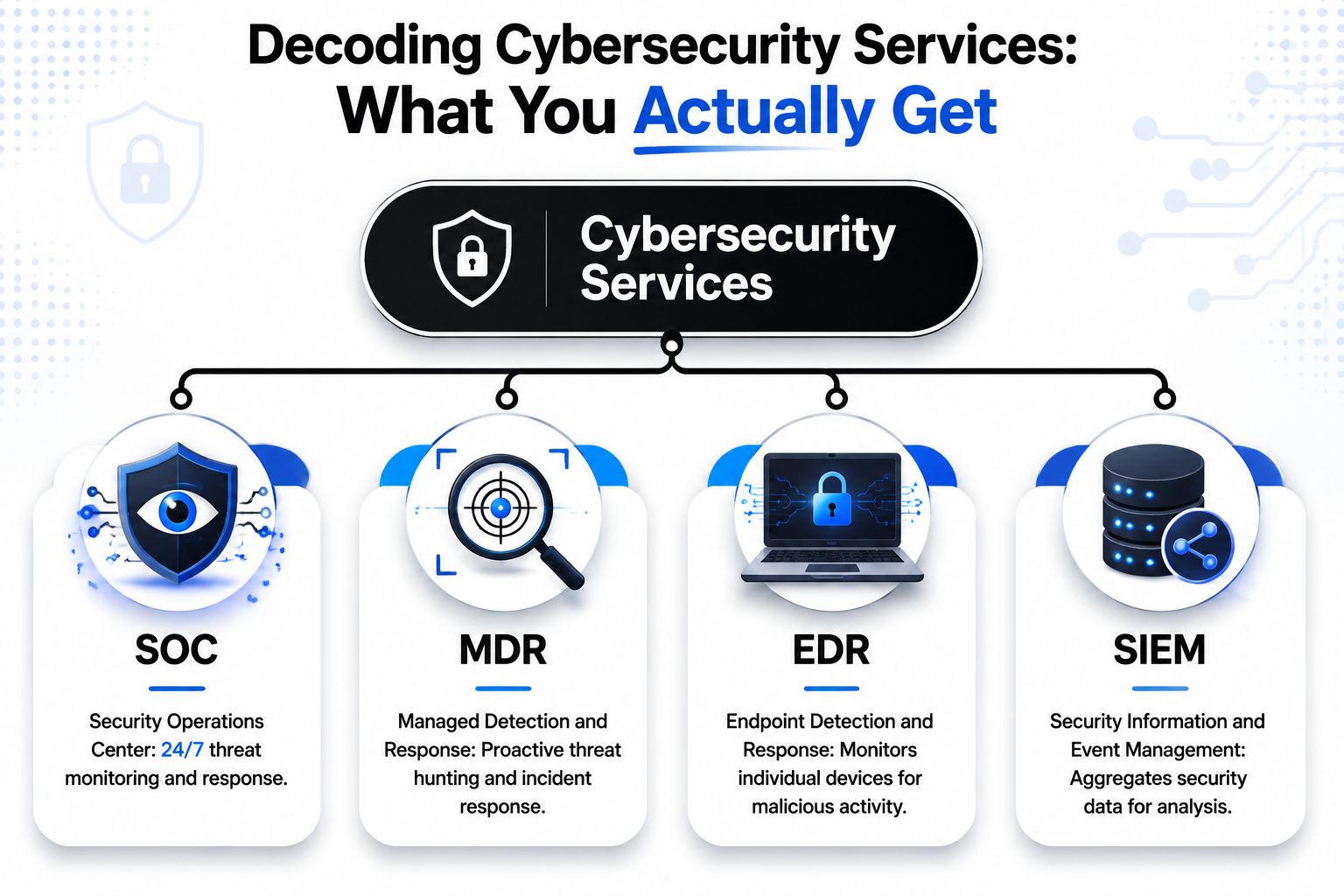
Continuous monitoring and a real SOC
Monitoring matters when alerts lead to action. Orlando businesses with after-hours operations, remote staff, or customer-facing systems need someone reviewing suspicious activity outside normal business hours and deciding what requires containment now versus investigation later.
For owners and operations leaders, the business case is straightforward. Faster review cuts downtime. Faster containment limits how many devices, accounts, or locations get pulled into the same incident. It also reduces the chaos that follows when leadership has no clear timeline or owner.
Ask direct questions. Who reviews alerts at 2 a.m.? What events trigger human escalation? How quickly can the provider isolate a device or disable a compromised account? If those answers are vague, the service probably looks better on paper than it performs in practice.
Incident response that holds up under pressure
A provider should be able to explain the first few hours of an incident in plain language. That includes who makes decisions, how evidence is preserved, when leadership is notified, and what records are created for insurance, legal review, and compliance.
A usable incident response function should include:
- Containment actions: isolate endpoints, disable accounts, block malicious traffic, and restrict lateral movement
- Evidence handling: preserve logs, endpoint data, and change records so the business can support a claim or investigation
- Recovery priorities: restore line-of-business systems in the right order instead of bringing everything back at once
- Executive communication: give leadership a clear status update, current risk, and next actions without technical clutter
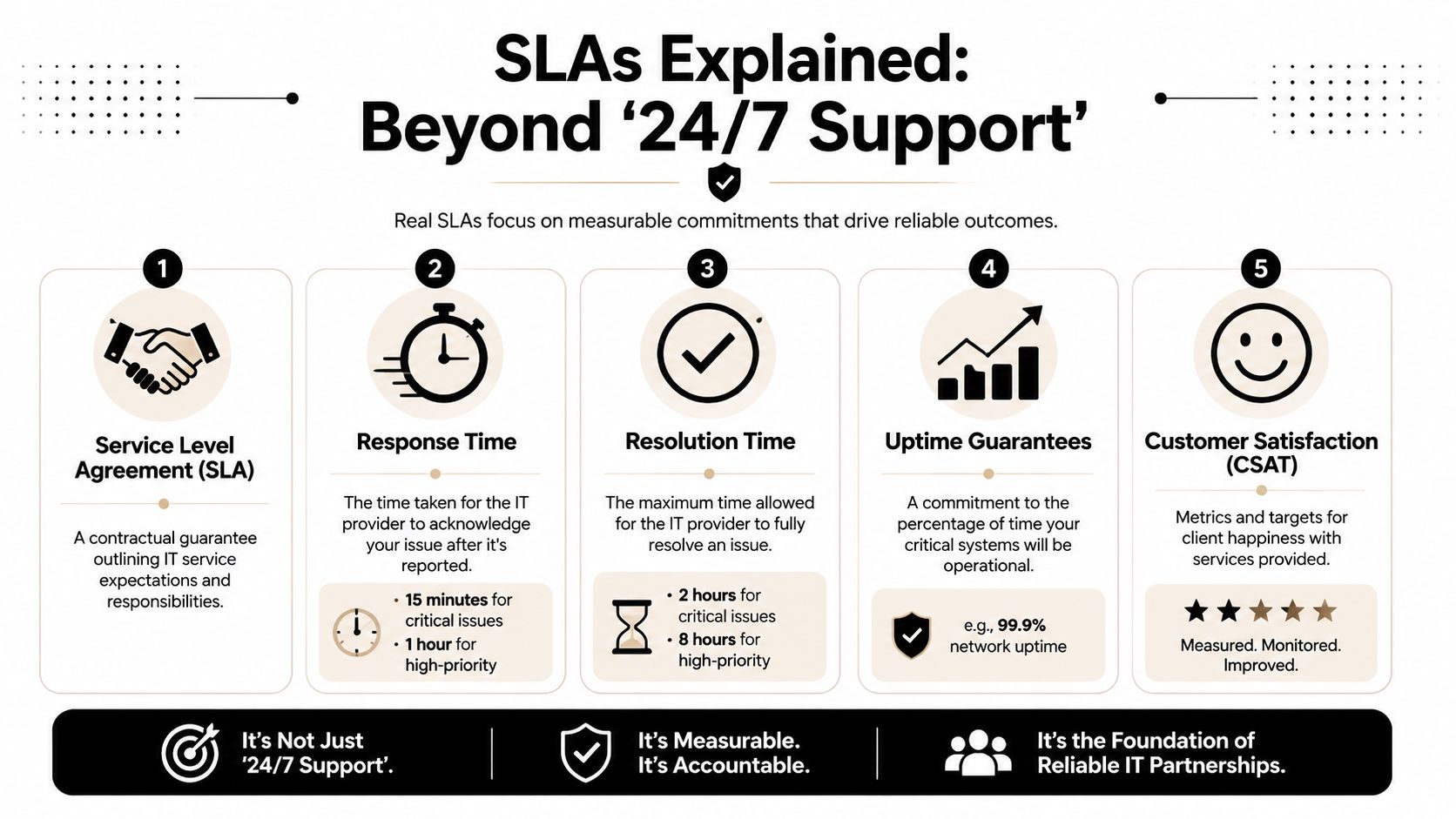
Many service agreements fall short. They cover alerting but not response labor, or they promise help during an incident without defining what help entails. Before signing, review the scope as carefully as the tools.
A strong provider also proves its work after the fact. You should be able to get incident timelines, remediation records, and policy evidence without chasing multiple teams. That paper trail matters when cyber insurance carriers or regulators ask for proof, not assurances.
Firewall management, endpoint protection, and vulnerability scanning
Firewall and endpoint controls need ongoing care. Rules drift after office moves, vendor access requests, cloud changes, and staffing turnover. Laptops miss patches. Remote devices fall outside normal review. One neglected system is often enough to create an entry point.
That is why routine scanning and remediation review belong in the core service set. A provider should show what was found, what was fixed, what remains open, and who owns the exception if something cannot be remediated quickly. Fivenines security scanning offers a useful example of the kind of visibility businesses should expect from a scanning program.
This work also affects budgeting. If you want a clearer view of how recurring security tasks and exception handling influence monthly costs, this breakdown of key factors influencing IT managed service pricing helps frame the discussion.
Phishing resistance and user controls
Email remains one of the cheapest ways to get into a business. Training helps, but annual presentations are not enough. Staff need short, repeated guidance on login prompts, payment changes, shared file requests, MFA fatigue attacks, and messages that create urgency.
User controls matter just as much as awareness. Security teams should be enforcing MFA, limiting local admin rights, reviewing risky sign-ins, and tightening access when roles change. Training without those controls leaves too much to individual judgment.
Cyber Command, LLC is one Orlando-area provider offering services such as EDR, SOC monitoring, firewall management, and MFA within managed IT and cybersecurity support. The larger point applies to any provider you consider. Choose one that can show response procedures, compliance evidence, and a clear path from detection to containment to recovery.
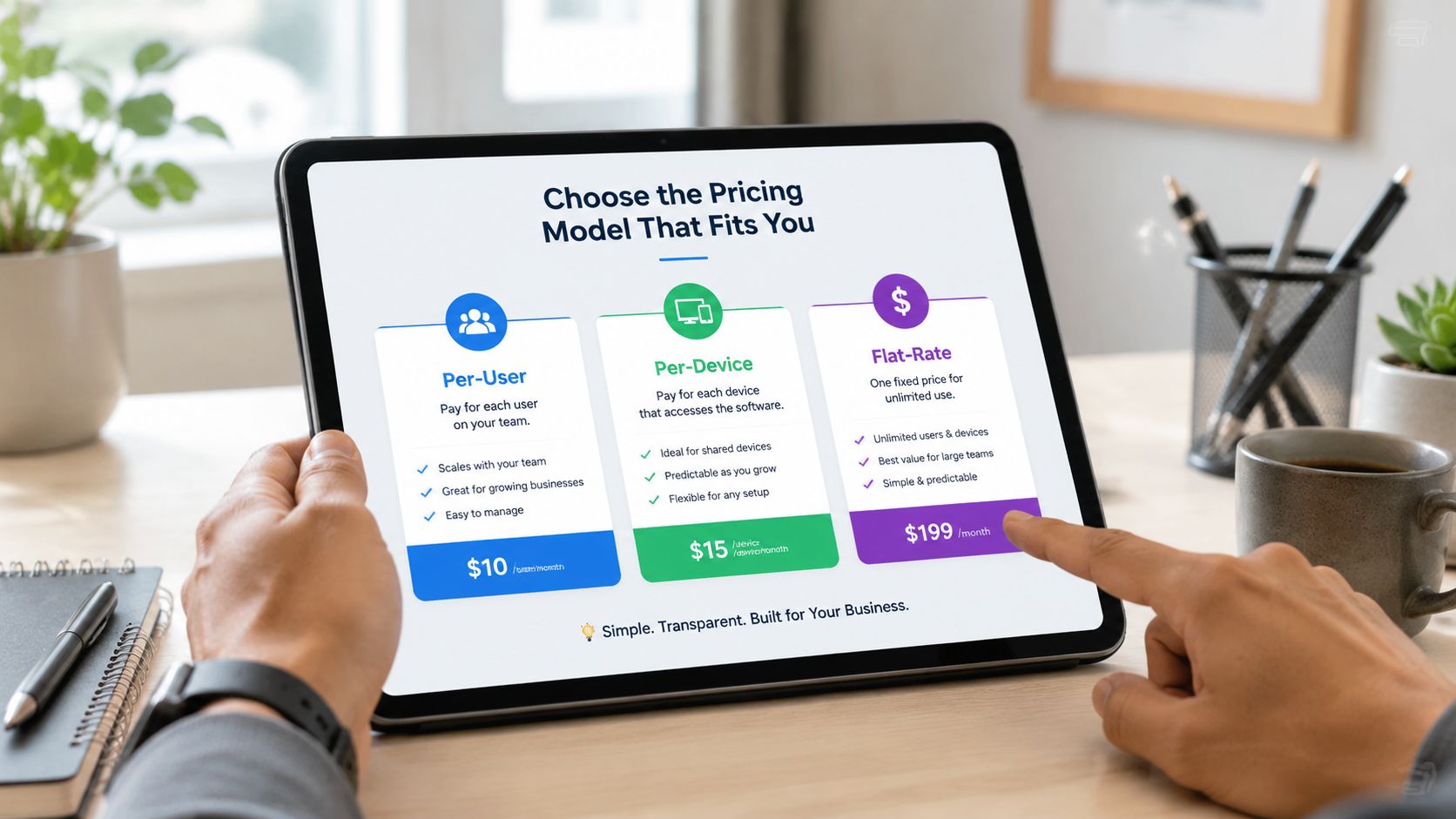
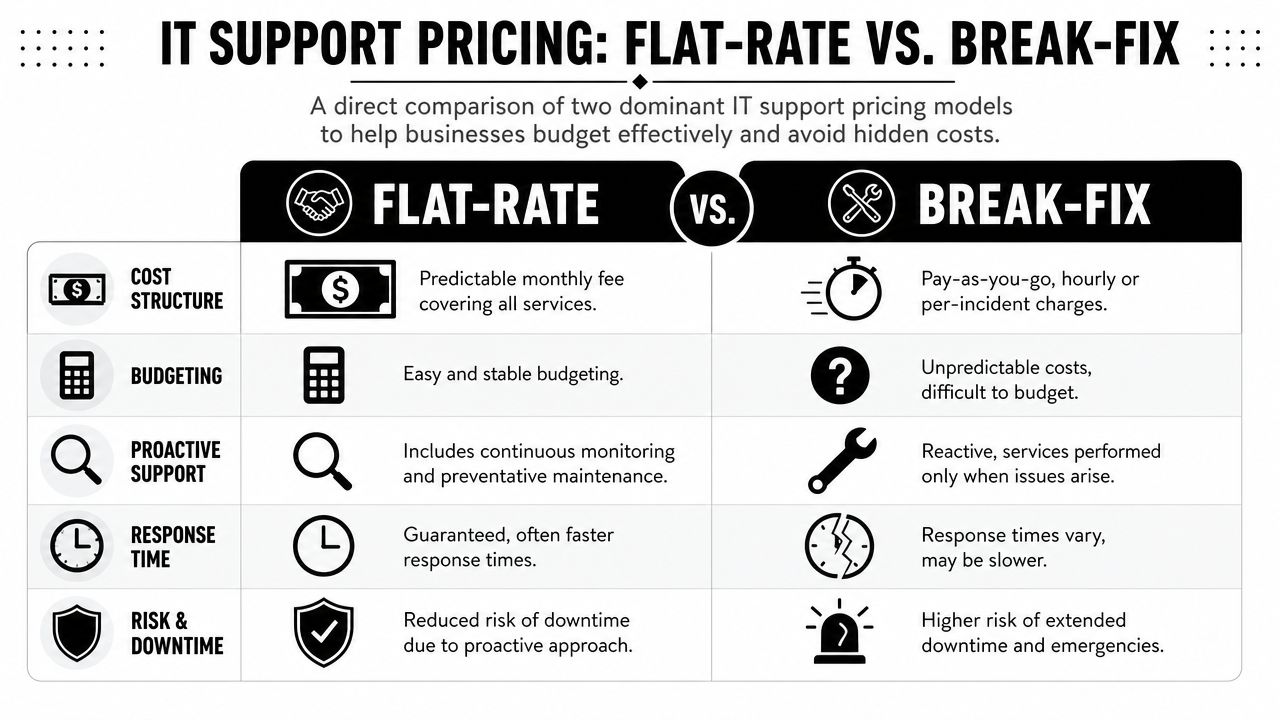
Decoding IT Security Pricing Predictability vs Hidden Fees
Security pricing gets messy fast because providers package services in different ways. One charges by user. Another charges by device. Another wraps most services into a flat monthly agreement but bills separately for projects or after-hours work. If you don't pin this down early, the “cheaper” proposal can become the expensive one.
The labor market explains part of this. The Bureau of Labor Statistics reports a median annual wage of $124,910 for information security analysts in May 2024, with employment projected to grow 29% from 2024 to 2034 and about 16,000 openings each year on average (BLS information security analyst outlook). For Orlando businesses, that helps explain why outsourced security has become standard. Hiring one internal security person is hard enough. Building round-the-clock coverage internally is a different level of cost and complexity.
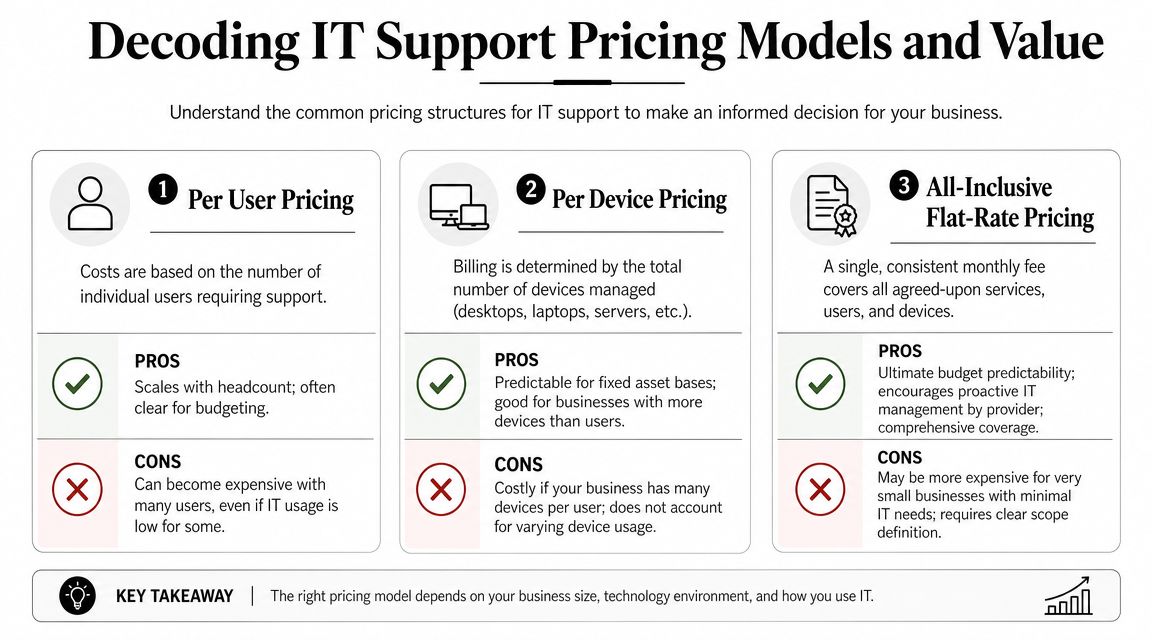
Comparing common pricing models
| Pricing Model | How It Works | Best For | Potential Downside |
|---|---|---|---|
| Per-user | Monthly fee based on employee count | Office-centric firms with predictable staffing | Shared devices, servers, and site systems may not fit neatly |
| Per-device | Fee tied to laptops, desktops, servers, and sometimes network gear | Environments where asset counts are stable and tightly managed | Costs can creep as devices, locations, and special systems get added |
| Flat-rate | One recurring fee covering an agreed service scope | Businesses that want budgeting stability and broad coverage | You must review scope carefully to see what's included versus excluded |
What to watch for in proposals
The issue isn't only price. It's cost predictability.
Look closely at these pressure points:
- After-hours response: Is emergency work included, limited, or separately billed?
- Projects and changes: Are office moves, migrations, or remediation tasks covered?
- Security stack components: Does the monthly fee include monitoring, response, reporting, and training, or just the software licenses?
- Compliance support: Will the provider help produce evidence for insurance and audits, or only deploy tools?
A broader breakdown of these trade-offs is covered in this guide to managed service pricing factors.
The practical buying decision
Per-user pricing can work well for a smaller professional office. Per-device pricing can fit firms with stable infrastructure and fewer swings in headcount. Flat-rate models usually make the most sense when leadership cares about budget consistency, broad accountability, and avoiding a surprise invoice during a bad month.
If you're buying IT Security Services in Orlando FL, ask a blunt question: what will I still get billed for when something goes wrong? That answer tells you more than the base monthly number.
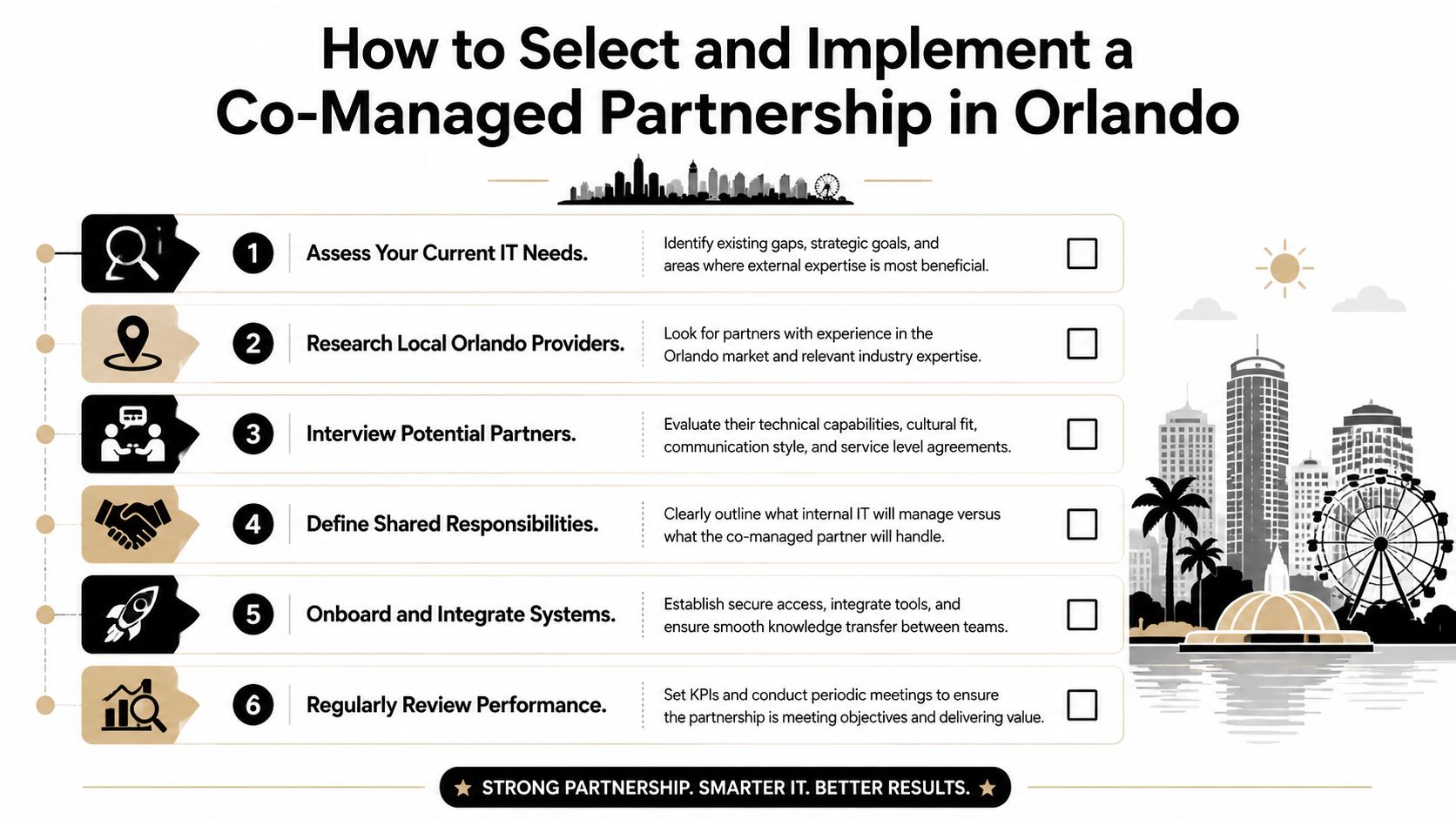
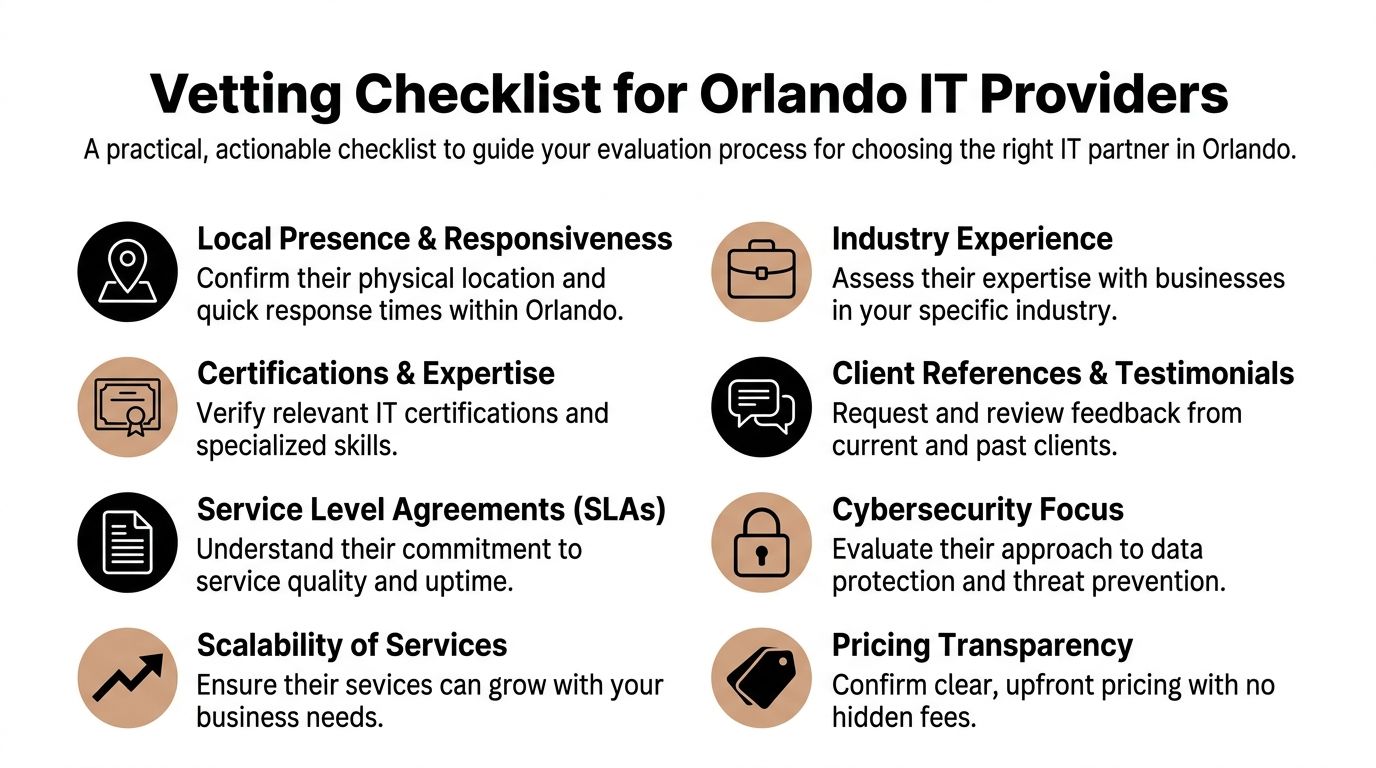
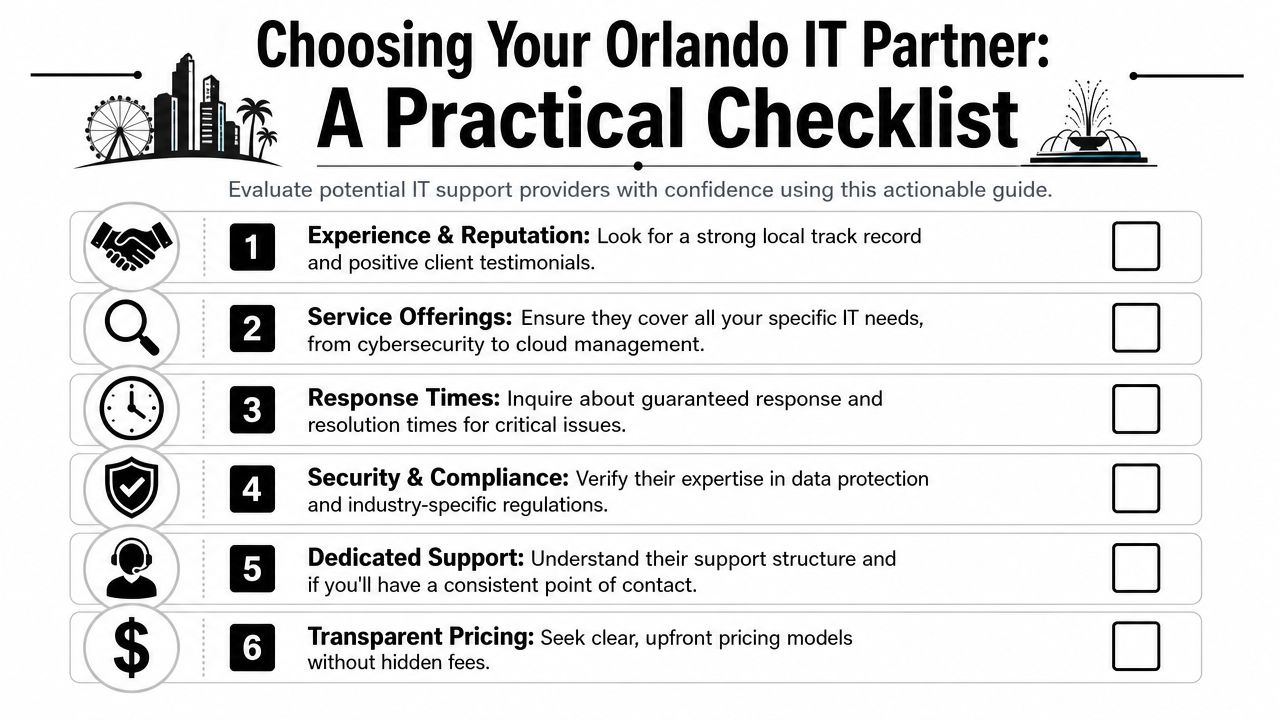
Choosing Your Orlando Security Partner Key Questions to Ask
Most providers can give you a service list. Fewer can give you evidence. That difference matters more now because cyber insurance, audits, and vendor reviews increasingly require proof that controls exist and are being maintained. For Orlando firms in professional services and healthcare, documentation such as patching records, MFA enforcement, and incident logs is often more valuable than a polished security brochure (compliance evidence and cyber insurance guidance).
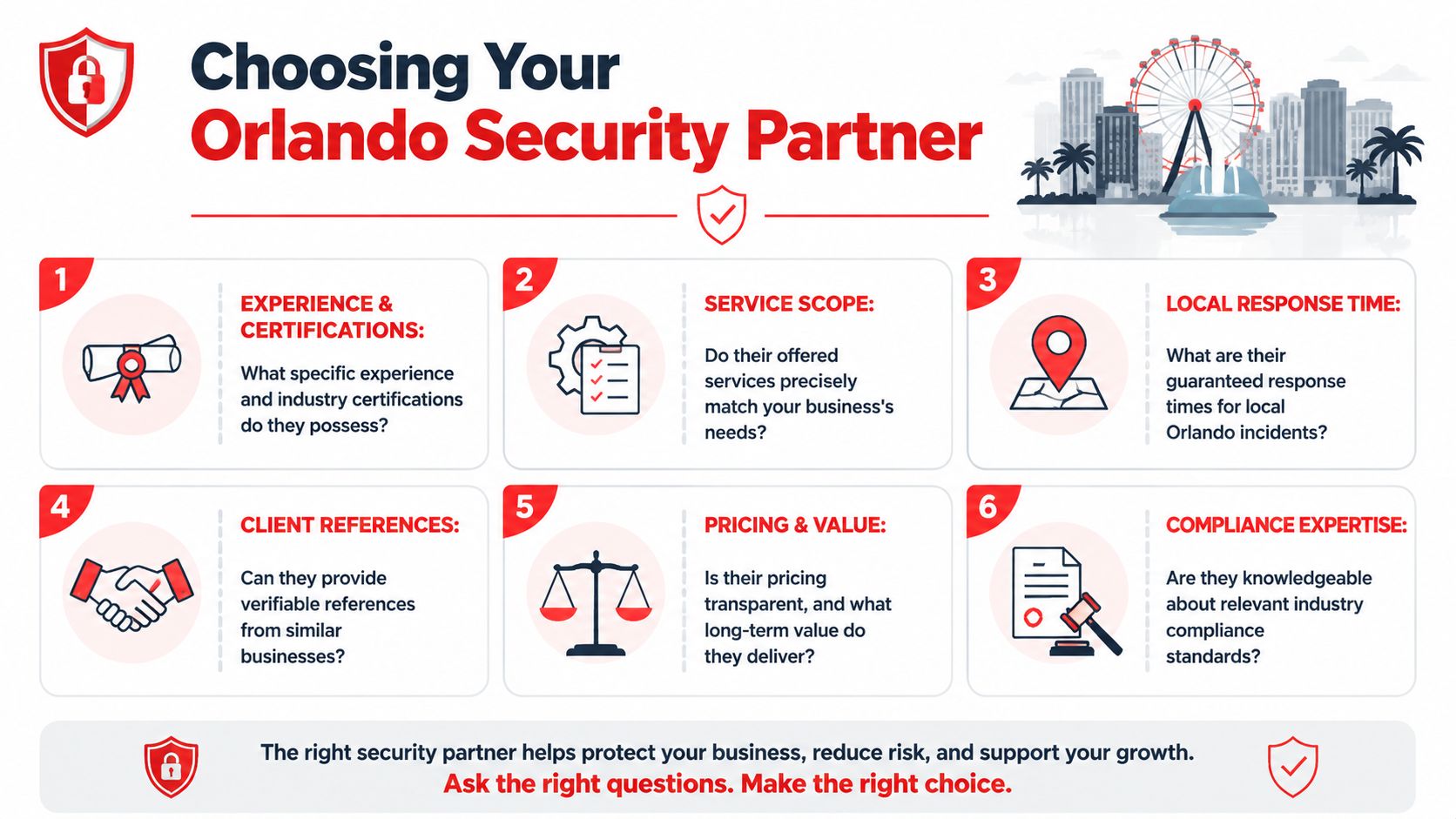
Ask for proof, not promises
A provider may say they “support compliance.” That phrase means nothing unless they can show what they produce and how often they produce it.
Ask these questions directly:
- Can you provide patching records? You need evidence that systems were updated, not just a verbal assurance.
- How do you verify MFA enforcement? Ask how they document protected accounts and exception handling.
- What incident logs do you retain? You want to know what's recorded, where it's stored, and who can access it.
- What happens during ransomware containment? Listen for a step-by-step answer, not vague reassurance.
- Who is staffed after hours? Clarify whether response is live and operational, or only on-call escalation.
Evaluate response maturity
A mature provider should be able to walk you through the first day of an incident in plain English. Not every answer needs to be highly technical. It does need to be coherent.
Look for signs of operational maturity:
- Clear triage path: Who reviews alerts first, who escalates, and who contacts your leadership team.
- Defined containment authority: Whether they can disable accounts, isolate endpoints, or block traffic immediately.
- Recovery discipline: Whether they prioritize business-critical systems rather than restoring everything at once.
- Documentation habits: Whether every major action is timestamped and preserved.
What good answers sound like: “Here's how we contain, document, recover, and report.”
Weak answers sound like: “We monitor things and let you know.”
Local fit still matters
Remote monitoring is standard. Local presence still matters when hardware fails, offices move, physical access systems tie into IT, or leadership wants in-person incident coordination. In Central Florida, that matters more than many buyers expect because many businesses run across offices, clinics, warehouses, or public-facing locations.
If you need a vetting framework before interviews, this guide on how to choose a managed service provider gives a useful starting point.
Industry-Specific Security Needs in Central Florida
Different industries buy security for different reasons. A law firm is protecting confidential client matters and billable time. A healthcare practice is protecting patient data and continuity of care. A multi-location operator is trying to secure users, networks, and devices across several sites without losing visibility.
Professional services firms
Law firms, accounting practices, architecture groups, and engineering firms usually depend on a mix of email, cloud files, document workflows, and client communication. Their biggest risk isn't just malware. It's unauthorized access to sensitive records, impersonation of trusted contacts, and silent account misuse that goes unnoticed until a client asks questions.
The most useful controls here are:
- Strong access policies: Limit who can reach financial records, client folders, and partner accounts.
- Centralized logging: Make it possible to investigate who accessed what and when.
- Email and identity protection: Reduce exposure to impersonation and account takeover.
- Evidence-ready reporting: Support insurance questionnaires, vendor due diligence, and client security reviews.
For these firms, security has to protect reputation as much as systems.
Healthcare practices
Medical, dental, veterinary, and elective-care practices have a different operating problem. They can't tolerate much downtime at the front desk, in scheduling, or in clinical systems. Their risk sits at the intersection of privacy, operations, and staff workflow.
Priorities usually include:
- MFA and account controls: Especially for email, remote access, and administrative accounts.
- Patch discipline: Clinical and office systems need a documented update process.
- Incident logging: Investigations need records, not memory.
- Recovery planning: Staff should know how the practice operates if one application is unavailable.
A healthcare office doesn't need unnecessary complexity. It needs consistent controls that staff can follow on a busy day.
Industrial and multi-location businesses
Industrial firms, field-service businesses, and operators with several sites face a wider attack surface. They may have office users, warehouse devices, cameras, access systems, shared workstations, and site-to-site connectivity. That means security can't live only on desktops.
These organizations often benefit most from:
- Network segmentation: Separate business systems, site infrastructure, and sensitive resources.
- Managed access control: Control physical and logical entry together where possible.
- Continuous monitoring across locations: See problems centrally instead of waiting for a site manager to report them.
- Standardized policy enforcement: Keep onboarding, patching, and device handling consistent across every office.
The common mistake is treating each site as its own island. Centralized visibility usually matters more than adding one more point product.
Frequently Asked Questions About IT Security
What's the difference between an MSP and an MSSP
A general managed service provider usually handles broad IT needs such as support, devices, user administration, and infrastructure upkeep. A managed security provider focuses more specifically on threat monitoring, incident response, containment, and security operations. Some firms combine both. What matters is whether they can show a real security workflow, not just general IT support with a security label.
My business is small. Do we really need this level of protection
Yes, but the level of complexity should match the business. A small firm doesn't need enterprise sprawl. It does need strong account security, endpoint protection, backup discipline, logging, and a defined response process. Small companies are often hit through ordinary channels such as phishing, reused passwords, and unmanaged devices. Basic maturity beats expensive chaos.
Smaller businesses usually don't need more tools first. They need fewer gaps.
How long does onboarding usually take
That depends on how organized your current environment is. Clean user records, documented devices, and known vendors make onboarding smoother. The core issue isn't speed alone. It's whether the provider can discover unknown assets, close obvious holes, and establish reporting without interrupting the business. A rushed onboarding that skips documentation usually creates problems later.
What should happen in the first hour of a suspected incident
The provider should confirm the alert, assess scope, start containment, preserve evidence, and communicate clearly with decision-makers. If they can't clearly explain those steps, they probably haven't operationalized response. During a real event, clarity matters more than marketing language.
If your business needs IT Security Services in Orlando FL, the next step isn't buying another standalone tool. It's getting a provider to show you how they monitor, respond, document, and support compliance in practice. Cyber Command, LLC works with Central Florida organizations that want predictable support, 24/7 coverage, and security operations tied to uptime, recovery, and accountability.