Orlando Cybersecurity Company: Your 2026 Buyer’s Guide

You're probably in one of two situations right now. Your business has an IT person or outside IT firm that handles passwords, printers, Microsoft 365, and the occasional outage, and you're hoping that also means you're “covered” on security. Or you've already had a scare. A suspicious email. A locked account. An employee clicking something they shouldn't have. A client asking for security documentation you don't have ready.
That's where many Central Florida businesses hit the same wall. General IT support keeps systems running. It doesn't always give you the layered protection, monitoring, documentation, and response discipline needed when your firm handles sensitive client records, protected health information, financial data, or industrial operations. In Orlando, Kissimmee, Winter Park, Sanford, and Winter Springs, that gap shows up differently by industry, but the business risk is the same.
If you're trying to choose an Orlando cybersecurity company, the decision gets easier once you stop thinking in generic IT terms and start looking at operational fit. A law office doesn't buy security the same way an industrial service firm should. A dental practice doesn't need the same reporting format as an executive team reviewing risk. The right partner matches protection to your actual business model, not a canned package.
Table of Contents
- Why Your Standard IT Guy Is Not Enough Anymore
- Building Your Cybersecurity Shopping List
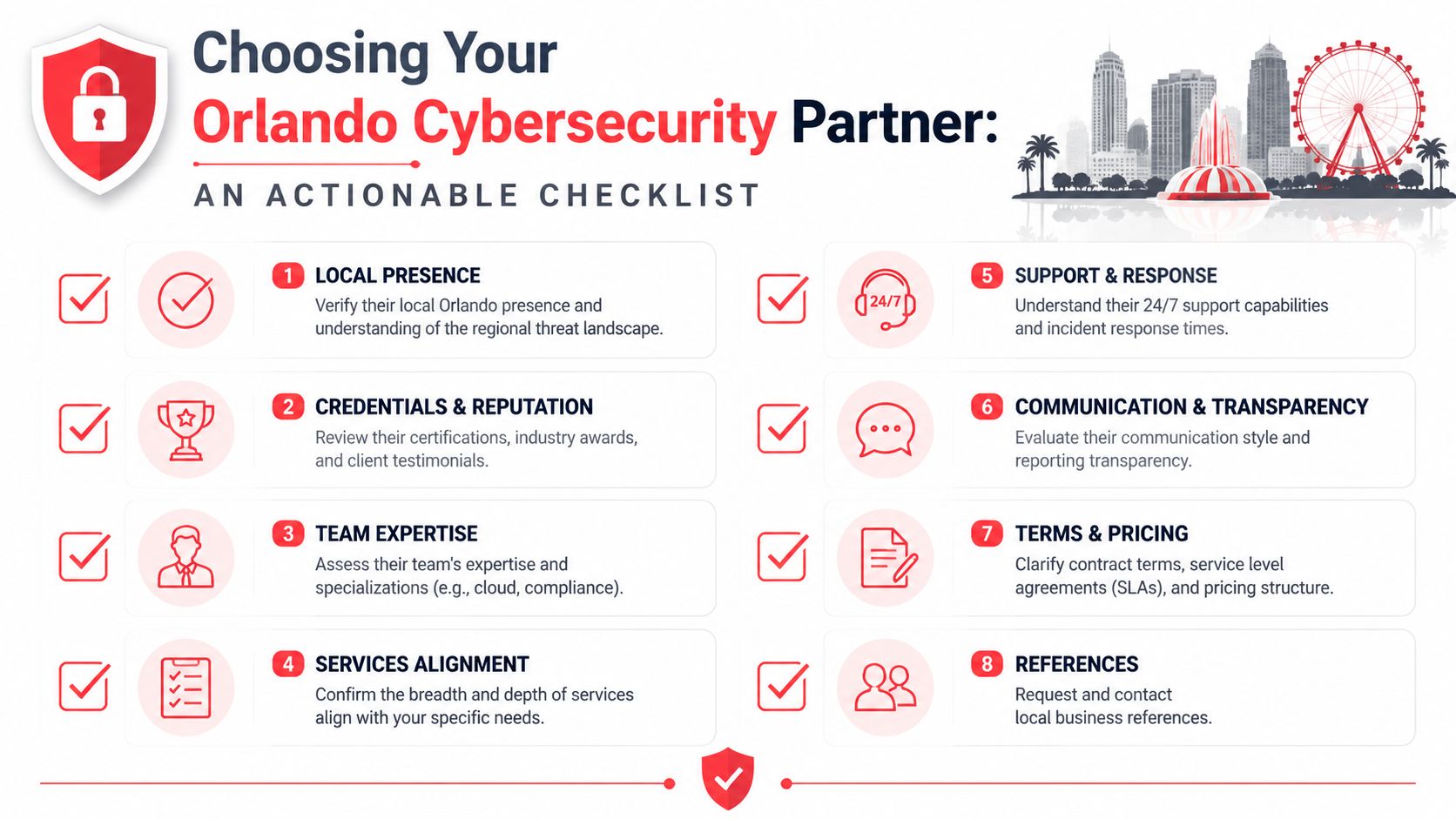
- The Orlando Cybersecurity Partner Evaluation Checklist
- Interview Questions That Reveal The Truth
- Decoding Pricing Contracts and Service Guarantees
- Seeing Success What The Right Partnership Looks Like
Why Your Standard IT Guy Is Not Enough Anymore
A business owner in Orlando usually notices the problem at the worst time. It's late Friday. An employee reports strange login prompts. File access gets weird. Email starts bouncing. The IT provider can reset passwords and open a support ticket, but nobody can answer the harder questions. Was this phishing? Did someone get into the mailbox? What systems touched that account? What needs to be isolated first? Who documents this for compliance if customer or patient data was exposed?
That's not a criticism of honest IT generalists. It's a recognition that cybersecurity has become its own operating discipline.
Florida small businesses face five primary cybersecurity threats: ransomware, phishing and social engineering, data breaches, insider threats, and compliance failures, as outlined in Cyber Command's Orlando cybersecurity services overview. Those risks don't stay neatly inside the server closet. They spill into billing, scheduling, legal exposure, reputation, and client trust.
Where the gap shows up first
For professional services firms, the weakness is often documentation and control maturity. The office may have antivirus and backups, but no clear proof that email protections are layered, remediation is tracked, or access controls are reviewed in a way that stands up during an audit.
For industrial and field-service organizations, the blind spot is different. Many have both cyber and physical exposure, and local guidance around Orlando IT security services points to a layered stack that can include video surveillance and managed access control alongside intrusion detection. If your cybersecurity conversation never touches doors, cameras, plant access, or field operations, it's incomplete for that environment.
A provider who only waits for users to report problems is doing IT support. A provider who hunts for threats, contains incidents, and produces usable evidence for leadership is doing security.
The business decision underneath the technical one
When owners search for an Orlando cybersecurity company, they often compare line items instead of operating models. That's where bad fits happen.
A reactive vendor closes tickets. A security partner looks for weak signals before users notice them. A generic provider may talk about tools. A strong provider talks about containment, recovery, reporting, and how your office will function Monday morning after a bad weekend event.
If your business is in healthcare, legal, accounting, architecture, engineering, or industrial services, “good IT” isn't the bar anymore. You need someone who understands both the threat and the consequence of that threat inside your industry.
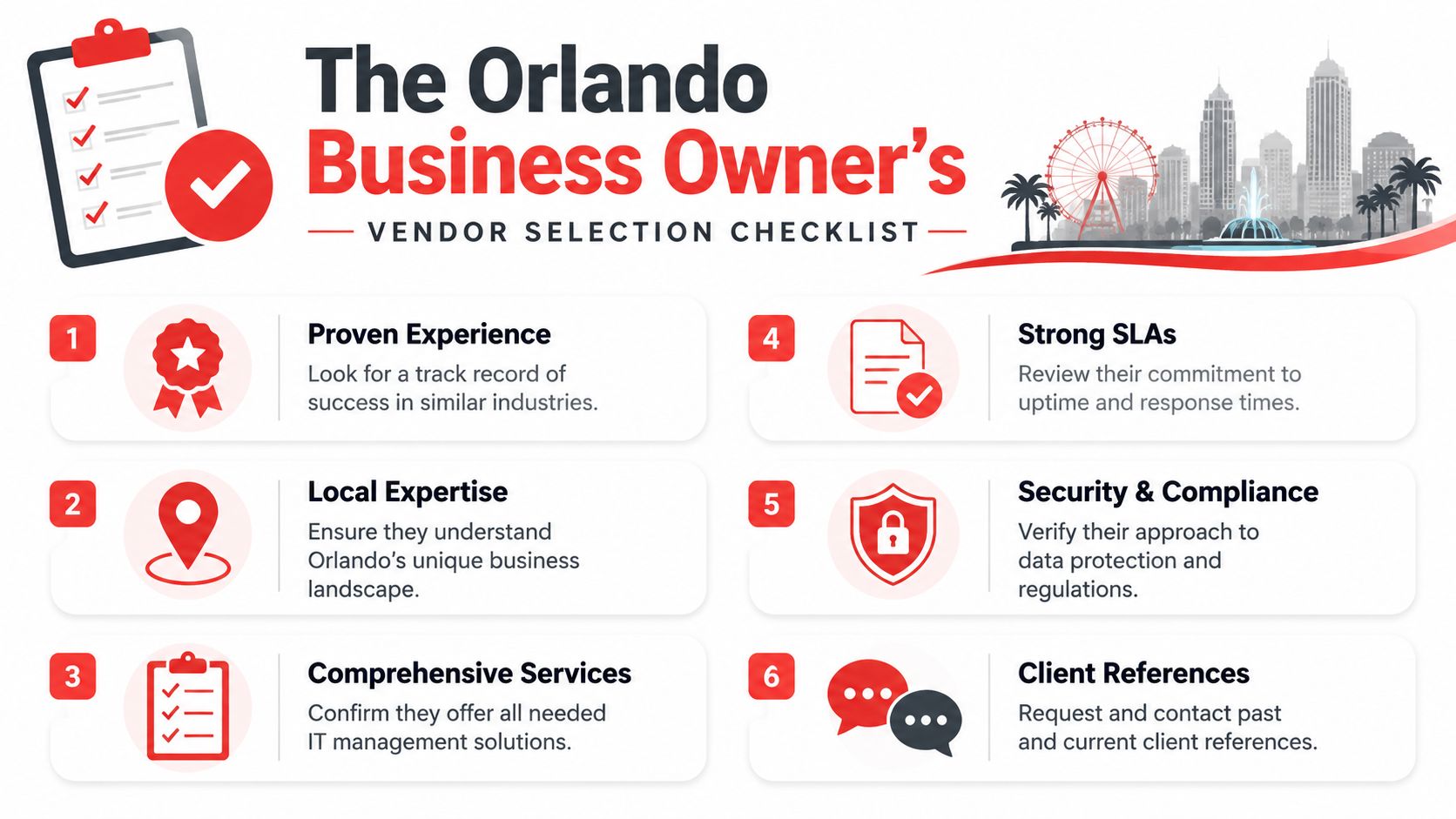
Building Your Cybersecurity Shopping List
A Winter Park law office gets hit with a mailbox takeover on Friday afternoon. By Monday, clients have received fake wire instructions, staff are locked out of cloud accounts, and leadership is asking a hard question: what security capabilities should have been in place before this happened?
That is the right way to build a buying list. Start with failure points your business can face, then map services to those risks.
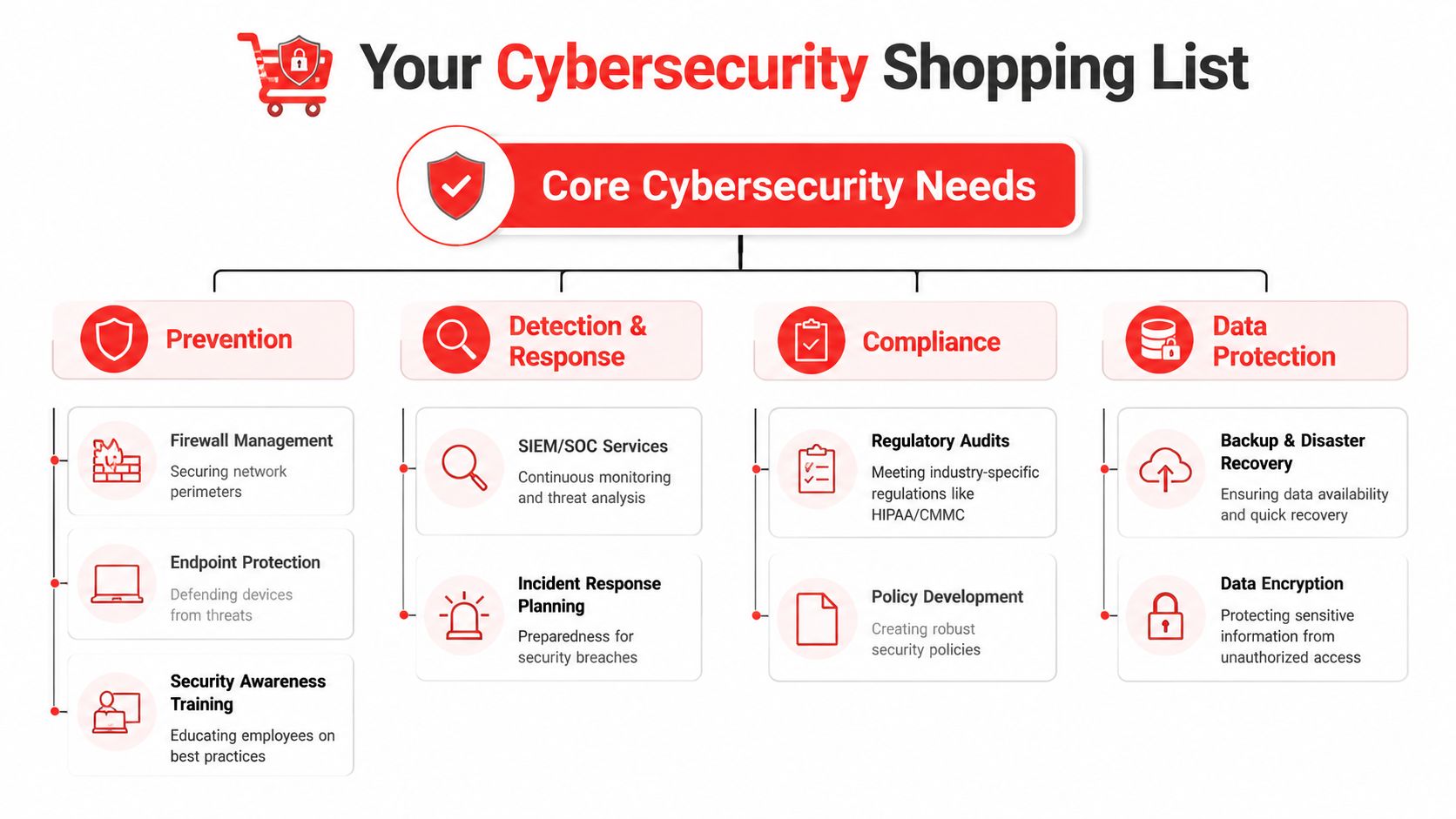
A useful reference is this security checklist graphic for managed protection planning. It reflects the categories a provider should be able to turn into daily operating discipline, not just a stack of tools.
What needs to be on the list
Start with the baseline controls that reduce avoidable incidents: firewall administration, endpoint protection, patch management, identity controls, and user awareness training. These are not glamorous purchases, but they cut down the number of routine openings attackers use.
Then look at detection and response. Orlando businesses often buy monitoring that creates alerts but does not create action. If your provider cannot investigate suspicious activity after hours, isolate a device, disable a compromised account, and document what happened, you have reporting, not response.
That gap matters fast. A compromised Microsoft 365 account can turn into invoice fraud. A laptop infection can reach shared files before anyone opens a help desk ticket. In industrial and field-service environments, the impact can extend beyond data. Remote access abuse, unmanaged shop-floor systems, and weak site access controls can affect production schedules, inventory systems, cameras, badge access, and field crews.
For regulated firms, the shopping list has to go further. Professional services companies in Orlando, including legal, accounting, engineering, and healthcare-adjacent practices, usually need security controls that also produce evidence. That means policy enforcement, access reviews, audit trails, retention settings, remediation records, and reporting leadership can hand to an auditor or client.
Hiring and staffing also affect this category. Teams that support regulated environments need people who understand controls, documentation, and compliance workflows, not just general IT support. That is one reason firms evaluating internal hires or outside help often review resources like GENTY recruitment for compliance.
Practical rule: if a provider can explain how they block threats but cannot show how they document controls, exceptions, and remediation, the program will struggle during audits and client security reviews.
Recovery belongs on the list too. Ask where backups live, how they are segmented from production, how often restores are tested, and who is responsible for declaring an incident and starting recovery. A backup job that shows green in a dashboard is not the same as a recovery process your team can execute under pressure.
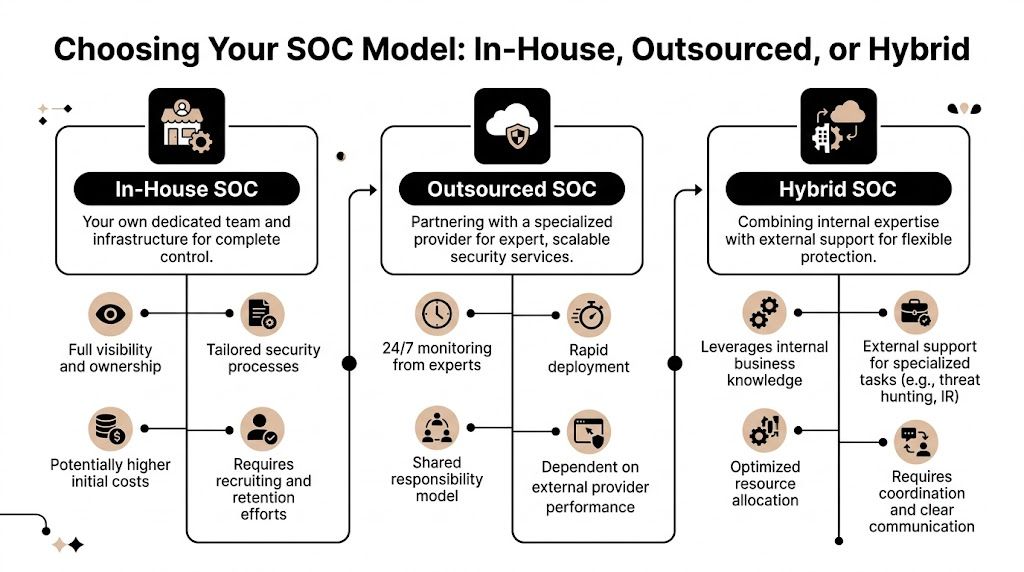
One local option businesses evaluate in this category is Cyber Command, LLC, a Winter Springs-based managed IT and cybersecurity firm. The better question is not which logo appears on the proposal. It is whether the provider can cover prevention, active response, recovery, compliance support, and the physical-digital overlap many Central Florida industrial firms deal with in their daily operations.
The Orlando Cybersecurity Partner Evaluation Checklist
A provider can sound sharp in a sales meeting and still fall apart during a real incident. In Orlando, that gap shows up fast. A law firm dealing with client data, a CPA office answering security questionnaires, and a manufacturer with connected equipment all need different controls, different reporting, and different response plans.

You will see plenty of polished sales material during your search, including a recognition graphic for Orlando cybersecurity services. Treat it as background, not proof. The actual test is whether the provider can explain how they protect your business, support your industry requirements, and operate under pressure.
What good looks like
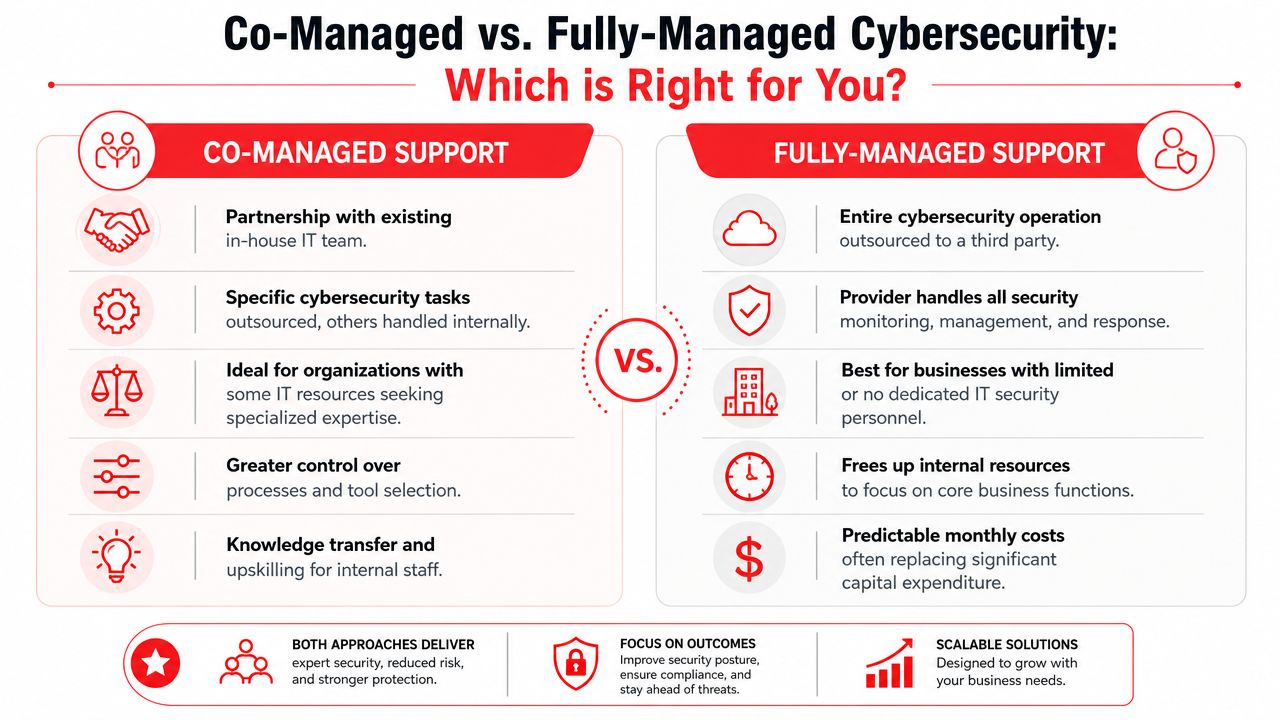
Start with local support, but define what that means. For some Orlando businesses, local matters because an executive wants face-to-face incident briefings. For industrial firms in Central Florida, it can mean someone showing up when a network issue touches production, badge systems, cameras, or facility access. Cyber Command, LLC is one example of a Winter Springs-based firm businesses may evaluate. Whatever company is on your shortlist, ask where their team works from, what can be handled on-site, and what still depends on remote support.
Industry fit matters more than broad security language. Professional services firms need a provider that can deal with client confidentiality, policy enforcement, retention rules, access reviews, and audit evidence without turning every request into a custom project. Industrial and field-service firms need a team that understands the overlap between cyber risk and physical operations. If a ransomware event affects dispatch, warehouse access, connected equipment, or plant-floor systems, the response cannot stop at resetting passwords and reimaging laptops.
A strong operating model is visible in the details. Ask how they handle triage after hours, who has authority to isolate a device, how they document exceptions, and how often they review control drift. If the answer stays at the level of ticket queues and antivirus deployment, you are still looking at general IT support with security add-ons.
Reporting should match the audience. Owners and executives need plain-language updates on business risk, open issues, and what needs a decision. Office managers and operations leaders need status, responsibilities, and timelines. Technical contacts need enough detail to verify what was detected, what was contained, and what still needs work. One generic dashboard sent to everyone usually means the provider has not built a mature service model.
Red flags that should slow you down
Some warning signs are technical. Others are operational, and those are often the ones that hurt businesses most during an incident.
| Evaluation area | Good sign | Red flag |
|---|---|---|
| Local support | Clear explanation of on-site availability, travel coverage, and response expectations | "We're local" with no service detail behind it |
| Industry fit | Can discuss your compliance duties or operational constraints in plain language | Uses the same pitch for law firms, medical offices, and industrial companies |
| Scope | Defines what is monitored, responded to, documented, and excluded | Broad promises with unclear ownership |
| Incident handling | Can explain first-hour actions, approvals, communication flow, and containment options | Tells you to open a ticket or call a general support line |
| Reporting | Gives leadership, compliance, and technical teams different views | Sends one generic report to every audience |
| Staffing | Names who reviews alerts, who leads incidents, and how after-hours coverage works | Relies on best-effort support or a vague shared queue |
Some companies also need help on the internal side, especially when growth creates gaps in policy ownership, audit readiness, or regulatory documentation. If you are adding oversight roles or tightening governance, GENTY recruitment for compliance is a useful reference for what compliance-focused hiring should cover.
A practical rule applies here. If a provider cannot explain what happens in the first hour of a serious incident, they probably have a sales process that is more mature than their operations.
The right partner makes trade-offs clear. They will tell you where automation helps, where human review is safer, and where your industry requires more documentation or tighter process than a standard IT package provides.
Interview Questions That Reveal The Truth
A 2:13 a.m. alert hits on a Friday. A staff mailbox is sending phishing emails, or a plant workstation starts talking to a server it should never reach. The sales version of support sounds fine until that moment. Your questions should test what the provider will do under pressure, how they document it, and whether their process fits the way your Orlando business operates.
Questions about operations under pressure
Ask for a step-by-step answer. If they stay vague, press for names, timing, and approvals.
What happens when a serious alert fires after business hours?
Look for a real workflow. Who receives the alert first, who confirms whether it is real, who contacts your team, and what they can contain before your office opens again.What can you isolate automatically, and what still requires human approval?
Good providers can explain where automation is safe and where it creates business risk. That matters for Orlando firms that cannot afford unnecessary disruption, especially medical practices, law offices, and industrial operations running fixed schedules or production windows.How do you reduce alert fatigue so real incidents are not buried?
The useful answer is operational, not marketing language. Ask how they tune detections, who reviews noisy alerts, how often rules are adjusted, and what gets escalated to a human analyst. If they point to certifications, dashboards, or a cloud partner badge example, ask what changed in day-to-day response quality because of that relationship.Describe your onboarding process for a firm our size and industry.
You want to hear more than agent deployment. A solid answer covers asset inventory, privileged access, email exposure, backup review, vendor access, remote work risk, and any compliance obligations tied to your business.
One short rule helps here. If they cannot describe the first hour clearly, they probably have not run enough incidents.
Questions about compliance and accountability
For professional services firms in Central Florida, weak providers get exposed fast. Law firms, accounting practices, wealth advisors, and healthcare groups all handle sensitive data, but they do not face the same documentation burden or client scrutiny. Ask questions that force the provider to separate security work from audit support.
- What evidence do you provide for audits, cyber insurance reviews, or client security questionnaires?
- How do you document remediation, exceptions, policy changes, and recurring risk issues?
- Which compliance tasks do you handle directly, and which stay with our internal team or outside counsel?
- How do you support mailbox security, account takeover prevention, and executive impersonation risk?
- What reporting goes to ownership, and what reporting goes to the people handling day-to-day operations?
A serious provider will answer in plain language. They should know that a managing partner wants business impact and open risk decisions, while an office manager or internal IT contact needs task-level detail and deadlines.
Questions for industrial and hybrid environments
Orlando area manufacturers, logistics firms, field service companies, and facilities operators need a different line of questioning. Their risk is not limited to email and file access. It often crosses into badge systems, cameras, vendor remote access, plant-floor devices, and shared credentials on aging equipment.
Ask these directly:
- How do you handle environments that include both office systems and operational equipment?
- What is your process when a cyber event affects production, shipping, building access, or safety systems?
- How do you work around legacy devices that cannot support standard security controls?
- How do you review third-party remote access used by maintenance vendors or equipment providers?
- What parts of the environment would you segment first, and why?
The right answer usually includes trade-offs. In industrial settings, immediate isolation can protect the network but interrupt operations. Sometimes that is the right call. Sometimes containment has to be staged around safety, production, and recovery reality. A provider that has worked in these environments will say that plainly.
Questions that expose misalignment early
A few business questions can save you months of frustration.
- How do you balance tighter controls with the way our staff work?
- What would you change in the first 90 days, and why those items first?
- Based on what you have heard so far, where do you think our biggest risk sits today?
- What habits or workflows would our team need to change for your security plan to work?
Clear answers matter more than polished ones. Good partners explain decisions, boundaries, and friction points before the contract is signed. That is how you tell whether you are buying real operational support or a nice presentation.
Decoding Pricing Contracts and Service Guarantees
A lot of cybersecurity contracts look simple until the first emergency, office change, or audit request. Then the exclusions start showing up.
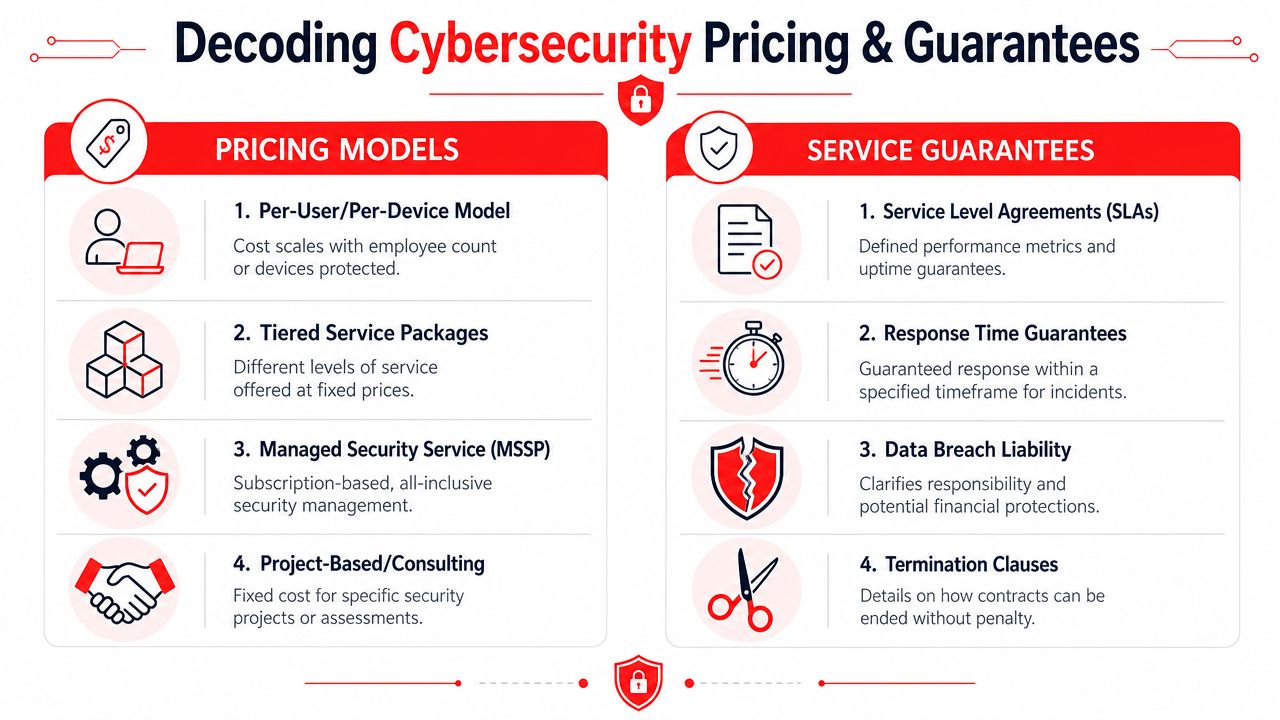
If a provider highlights partner status or platform relationships, you may see visuals like this cloud partner badge example. Those badges can signal ecosystem familiarity, but they don't tell you how billing behaves when you need help.
How pricing models behave in the real world
Most proposals fall into a few patterns.
Per-user or per-device pricing is easy to understand. It can work well for stable office environments. The downside is that costs can become fragmented if key protections, remediation work, projects, or compliance tasks sit outside the recurring fee.
Tiered packages look tidy on paper, but they can create awkward decisions. A growing firm may discover that the package it bought doesn't include enough reporting depth, incident response support, or backup oversight.
All-inclusive managed service pricing offers more predictability if the scope is clearly written. That model is often a better fit for businesses that want fewer surprise bills and tighter alignment between support and security. But “all-inclusive” only means something if the exclusions are narrow and explicit.
Project-based consulting is useful for assessments, policy work, remediation planning, or one-time compliance efforts. It's usually not enough by itself for an ongoing threat environment.
What to read carefully before you sign
Read the service agreement like a crisis document, not a brochure.
- Response terms: Does the contract distinguish between a general support issue and a security incident?
- Remediation ownership: Who performs containment, cleanup, recovery, and user communication?
- Licensing language: Are core protections bundled, or can the provider increase your cost later through add-on licensing?
- Project exclusions: Office moves, infrastructure upgrades, major remediation, and audit preparation often trigger separate fees.
- Termination terms: If the relationship goes sideways, how hard is it to leave with your documentation, configurations, and data intact?
The best contract language removes ambiguity before there's stress. The worst language sounds flexible until a real incident forces interpretation.
Service guarantees need the same scrutiny. A fast first response is useful, but it isn't the whole story. If the agreement says someone will “respond” quickly, ask what that word means. Acknowledging a ticket is not the same as beginning containment. Logging an alert is not the same as mobilizing action.
Also look for plain ownership language around backups, testing, compliance reporting, and third-party coordination. Many business owners assume these things are included because they were discussed in sales meetings. If they aren't written into the contract, treat them as uncertain.
A clean agreement doesn't have to be short. It has to be specific.
Seeing Success What The Right Partnership Looks Like
The difference between a vendor and the right partner usually shows up in ordinary business moments, not dramatic marketing stories.

Three local scenarios that show the difference
A Kissimmee law firm gets asked for security documentation during a client review. The wrong provider talks about antivirus, firewalls, and generic best practices. The right one produces policy records, remediation evidence, access control documentation, and a clear explanation of how the firm's layered controls support audit readiness. That's why the compliance-first security stack matters for regulated SMBs. As noted in Cyber Command's Central Florida compliance-focused guidance, these firms don't need “hacking” services first. They need proof of security for regulators.
A Sanford-area industrial company is standardizing infrastructure across office and operational environments. The weak approach secures endpoints and email but ignores the physical side of risk. The stronger approach coordinates digital controls with facility access, surveillance awareness, and operational continuity. For firms with field crews, yards, equipment, and shop space, cybersecurity can't stop at the login screen.
An Orlando medical practice gets hit by a phishing attempt that reaches staff inboxes early in the day. Good security doesn't mean nobody ever clicks. It means the practice has layered defenses, staff awareness, response discipline, and recovery procedures that keep disruption contained. The office manager knows who to call. Leadership gets an explanation they can understand. The business keeps moving.
For advisory and professional service firms trying to improve client-facing trust while tightening internal process, this 2026 compliance guide for advisors offers a useful lens on how service expectations and compliance discipline increasingly overlap.
The best outcome isn't flashy. It's steadier operations, fewer surprises, cleaner audits, and less executive time spent chasing avoidable problems.
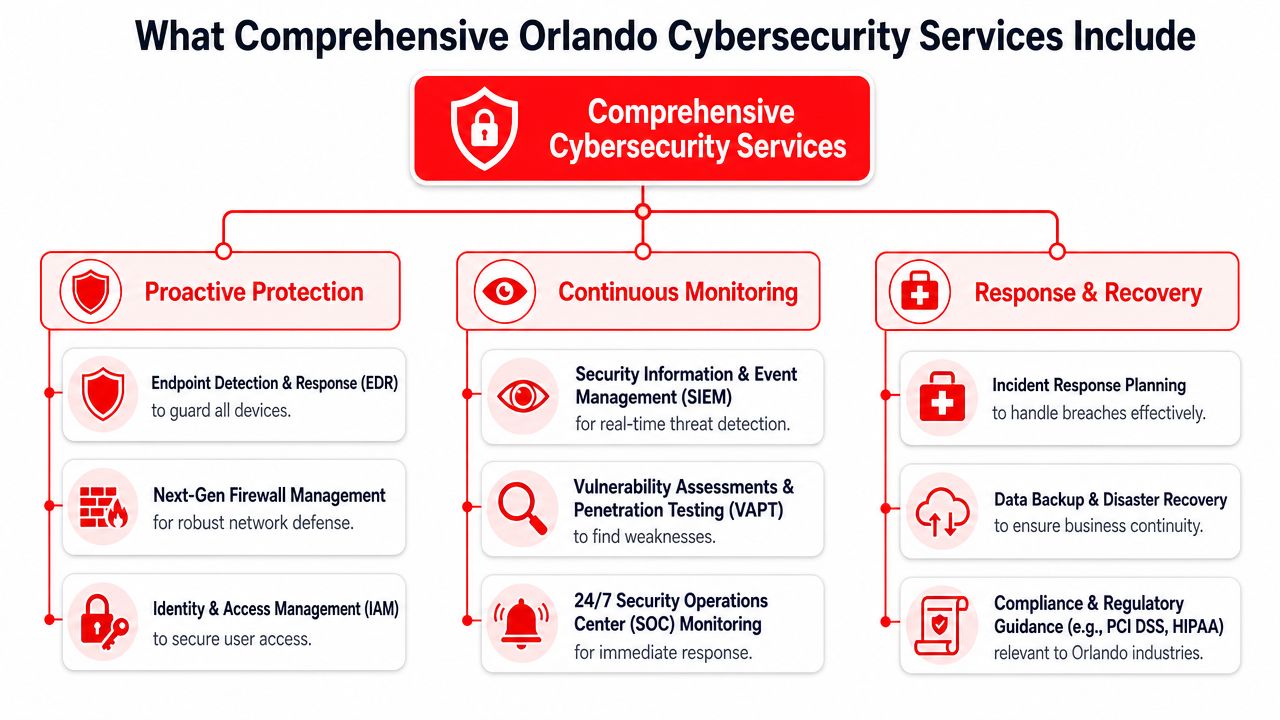
If you're evaluating an Orlando cybersecurity company and want a practical conversation about compliance, incident response, backup resilience, and industry-specific risk in Central Florida, Cyber Command, LLC is one local option to consider. The firm is headquartered in Winter Springs, Florida, has been operating since 2015, and provides managed IT and cybersecurity support with a dedicated 24/7/365 SOC for small and midsized businesses in the Orlando area.






















{kind=link}
{kind=link}
{kind=link}